
Unidad central de procesamiento para niños



La unidad central de procesamiento (conocida como CPU, del inglés central processing unit) o procesador es una parte muy importante del hardware dentro de un ordenador, teléfonos inteligentes y otros aparatos programables.
Su trabajo es entender las instrucciones de un programa informático. Para ello, realiza operaciones básicas de matemáticas, lógica y otras que vienen de los dispositivos de entrada y salida. El diseño de los procesadores ha mejorado mucho desde que se crearon. Ahora son más eficientes, potentes y usan menos energía.
Un ordenador puede tener más de una CPU (esto se llama multiprocesamiento). Hoy en día, los microprocesadores suelen ser un solo circuito integrado (un "chip"). También existen los procesadores multinúcleo, que tienen varias CPU en un solo chip. Un chip que contiene una CPU también puede incluir otros componentes del sistema. A esto se le llama sistema en un chip (SoC).
Las partes principales de una CPU son:
- Unidad Aritmético Lógica (ALU): Hace las operaciones de matemáticas (como sumar o restar) y de lógica (como comparar números).
- Unidad de Control (CU): Dirige el flujo de información dentro de la CPU. También conecta la ALU con las instrucciones que vienen de la memoria.
- Registros internos: Son pequeños espacios de memoria muy rápidos dentro de la CPU. Guardan información temporalmente para que la CPU pueda trabajar más rápido.
Contenido
¿Cómo empezó la historia de los procesadores?

Los primeros ordenadores, como el ENIAC, necesitaban ser conectados de forma diferente para cada tarea. Eran como "ordenadores de programa fijo". El concepto de "CPU" como lo conocemos hoy, que ejecuta programas, apareció con los ordenadores que podían guardar programas en su memoria.
La idea de un ordenador que guardara programas ya existía en los diseños de John Presper Eckert y John William Mauchly para el ENIAC. Sin embargo, esta característica se dejó de lado al principio para que el ENIAC estuviera listo antes. El 30 de junio de 1945, antes de que se construyera el ENIAC, el matemático John von Neumann compartió un informe sobre el EDVAC. Este informe describía un ordenador que guardaba programas, y el EDVAC se terminó en agosto de 1949. El EDVAC fue diseñado para realizar varias instrucciones. Lo importante es que los programas para el EDVAC se guardaban en la memoria rápida del ordenador. Esto solucionó un gran problema del ENIAC, que era el tiempo que se tardaba en reconfigurarlo para cada nueva tarea. Con el diseño de von Neumann, cambiar el programa (o software) del EDVAC era tan sencillo como cambiar el contenido de su memoria.
Sin embargo, el EDVAC no fue el primer ordenador con programa almacenado. La Máquina Experimental de Pequeña Escala de Mánchester, un prototipo, ejecutó su primer programa el 21 de junio de 1948. Su sucesor, el Manchester Mark I, lo hizo en junio de 1949.
Al principio, las CPU se diseñaban de forma personalizada para cada ordenador grande. Pero esta forma de trabajar ha cambiado mucho. Ahora se desarrollan procesadores más baratos y estandarizados para muchos usos. Esta tendencia empezó con los transistores y los circuitos integrados (IC). Los ICs permitieron crear CPU más complejas en espacios muy pequeños, del tamaño de nanómetros. Gracias a esta miniaturización y estandarización, los procesadores digitales están en muchos más aparatos hoy en día. Los microprocesadores modernos se encuentran en todo, desde automóviles hasta teléfonos móviles y juguetes.
Aunque John von Neumann es muy conocido por el diseño de ordenadores con programa almacenado, otros como Konrad Zuse ya habían propuesto ideas similares. La arquitectura Harvard del Harvard Mark I también usaba un diseño de programa almacenado, pero con cinta de papel perforada en lugar de memoria electrónica. La principal diferencia es que la arquitectura Harvard separa las instrucciones de los datos en la memoria, mientras que la de von Neumann usa el mismo espacio para ambos. La mayoría de las CPU modernas usan el diseño de von Neumann.
Los primeros ordenadores usaban relés eléctricos y tubos de vacío (válvulas termoiónicas) para sus interruptores. Un ordenador necesitaba miles de estos. La velocidad de un sistema dependía de la velocidad de estos interruptores. Los ordenadores de tubos, como el EDVAC, eran más rápidos pero fallaban más a menudo. Los ordenadores de relés, como el Harvard Mark I, eran más lentos pero más fiables. Al final, las CPU basadas en tubos se hicieron más populares por su gran ventaja en velocidad. Estas primeras CPU funcionaban a velocidades de reloj bajas, entre 100 kHz y 4 MHz.
Procesadores con transistores y circuitos integrados

El diseño de las CPU se hizo más complejo a medida que los componentes electrónicos se volvieron más pequeños y fiables. La primera gran mejora llegó con el transistor. Las CPU con transistores, de los años 1950 y 1960, ya no necesitaban los grandes y frágiles tubos de vacío. Con esta mejora, se construyeron CPU más complejas y fiables en una o varias tarjetas de circuito impreso con componentes individuales.
En este tiempo, se hizo popular fabricar muchos transistores en un espacio pequeño. El circuito integrado (IC) permitió poner una gran cantidad de transistores en una sola lámina de semiconductor o "chip". Al principio, solo se miniaturizaban circuitos digitales muy básicos en los ICs. Las CPU que usaban estos ICs se llamaban dispositivos de pequeña escala de integración (SSI). Los ICs SSI, como los del ordenador guía del Apolo, tenían decenas de transistores. Construir una CPU completa con ICs SSI requería miles de chips, pero aun así ocupaba mucho menos espacio y energía que los diseños anteriores. A medida que la tecnología mejoró, se pudieron poner más transistores en los ICs. Los circuitos integrados MSI y LSI (de mediana y gran escala de integración) aumentaron el número de transistores a cientos y luego a miles.
En 1964, IBM lanzó su arquitectura de ordenador System/360. Esta arquitectura se usó en una serie de ordenadores que podían ejecutar los mismos programas a diferentes velocidades. Esto fue muy importante, ya que en ese momento la mayoría de los ordenadores eran incompatibles entre sí. Para lograr esto, IBM usó el concepto de microprograma, que todavía se usa mucho en las CPU modernas. La arquitectura System/360 fue tan popular que dominó el mercado de los ordenadores grandes por décadas. En el mismo año, Digital Equipment Corporation (DEC) lanzó el PDP-8, un ordenador muy influyente para la ciencia. Más tarde, DEC introdujo la popular línea PDP-11, que al principio se construyó con ICs SSI, pero luego con componentes LSI. La primera versión LSI del PDP-11 tenía una CPU hecha con solo cuatro circuitos integrados LSI.
Los ordenadores basados en transistores tenían varias ventajas. Eran más fiables, usaban menos energía y eran mucho más rápidos. Las CPU de transistores podían alcanzar frecuencias de reloj de decenas de megahercios. Además, empezaron a aparecer nuevos diseños de alto rendimiento, como los procesadores vectoriales SIMD (single instruction multiple data – una instrucción, múltiples datos). Estos diseños experimentales llevaron a la era de los superordenadores.
Microprocesadores


En la década de 1970, los inventos de Federico Faggin cambiaron para siempre el diseño de las CPU. Desde la llegada del primer microprocesador comercial, el Intel 4004, en 1970, y del primer microprocesador muy usado, el Intel 8080, en 1974, esta clase de CPU ha reemplazado casi por completo a las otras formas de hacer procesadores. Los fabricantes de ordenadores grandes y miniordenadores empezaron a desarrollar sus propios chips para actualizar sus sistemas. Con el gran éxito del ordenador personal, el término "CPU" ahora se refiere casi siempre a los microprocesadores.
Las CPU anteriores se hacían con muchos componentes individuales y circuitos integrados pequeños en varias tarjetas. Los microprocesadores, en cambio, son CPU fabricadas con muy pocos ICs, normalmente solo uno. Al ser más pequeños, los microprocesadores son más rápidos. Esto ha permitido que los microprocesadores sincrónicos funcionen a velocidades de reloj que van desde decenas de megahercios hasta varios gigahercios. Además, como se pueden construir transistores muy pequeños en un chip, la complejidad y el número de transistores en una CPU también han aumentado mucho. Esta tendencia se describe en la ley de Moore, que ha sido una predicción muy precisa del crecimiento de la complejidad de las CPU.
Aunque la complejidad, el tamaño y la forma de las CPU han cambiado mucho en los últimos sesenta años, su diseño y funcionamiento básico no han cambiado tanto. Casi todas las CPU actuales se pueden describir como máquinas de programa almacenado de von Neumann. A medida que la ley de Moore sigue cumpliéndose, surgen preocupaciones sobre los límites de la tecnología de transistores. La miniaturización extrema de los componentes electrónicos está haciendo que algunos fenómenos físicos sean más importantes. Esto lleva a los investigadores a buscar nuevos métodos de computación, como la computación cuántica, y a usar más el paralelismo.
¿Cómo funciona un procesador?
La función principal de la mayoría de las CPU es ejecutar una serie de instrucciones guardadas, llamadas "programa". El programa es una secuencia de números que se guardan en la memoria del ordenador. Hay cuatro pasos que casi todas las CPU con arquitectura de von Neumann usan para funcionar: fetch (leer), decode (decodificar), execute (ejecutar) y writeback (escribir).

Leer (Fetch)
El primer paso, leer, consiste en obtener una instrucción (que es un número o una secuencia de números) de la memoria del programa. La ubicación de la instrucción en la memoria la determina un contador de programa (PC). Este contador guarda un número que indica la dirección de la siguiente instrucción a leer. Después de leer una instrucción, el PC aumenta su valor para apuntar a la siguiente instrucción en la secuencia. A menudo, la CPU tiene que esperar a que la instrucción llegue de la memoria, que es relativamente lenta. Los procesadores modernos resuelven esto con cachés y arquitecturas de tubería (pipeline).
Decodificar (Decode)
En el paso de decodificación, la instrucción se divide en partes que tienen significado para las otras unidades de la CPU. La forma en que se interpreta el valor numérico de la instrucción la define la arquitectura del conjunto de instrucciones (ISA) de la CPU. Generalmente, un grupo de números en la instrucción, llamado opcode, indica qué operación se debe realizar. Las partes restantes del número suelen dar la información necesaria para esa instrucción, como los números para una operación de suma. Estos números pueden ser un valor fijo o una ubicación donde encontrar el valor, que puede ser un registro o una dirección de memoria. En diseños más antiguos, las unidades de la CPU que decodificaban las instrucciones eran componentes fijos. Sin embargo, en CPU e ISAs más complejos, a menudo se usa un microprograma para ayudar a traducir las instrucciones en señales para la CPU. Este microprograma a veces se puede modificar para cambiar cómo la CPU decodifica las instrucciones, incluso después de haber sido fabricada.
Ejecutar (Execute)

Después de leer y decodificar, se realiza el paso de ejecución de la instrucción. Durante este paso, varias unidades de la CPU se conectan para realizar la operación deseada. Por ejemplo, si se pidió una suma, la unidad aritmético lógica (ALU) se conecta a unas entradas y unas salidas. Las entradas reciben los números a sumar, y las salidas mostrarán el resultado. La ALU contiene los circuitos para hacer operaciones matemáticas y lógicas simples. Si el resultado de la suma es demasiado grande para la CPU, se puede activar una "bandera" (flag) de desbordamiento.
Escribir (Writeback)
El último paso, escribir, simplemente guarda los resultados del paso de ejecución en alguna dirección de memoria. Muy a menudo, los resultados se guardan en un registro interno de la CPU para un acceso rápido por las siguientes instrucciones. En otros casos, los resultados pueden guardarse en la memoria principal, que es más lenta pero más barata y grande. Algunos tipos de instrucciones cambian el contador de programa en lugar de producir datos. Estas se llaman "saltos" (jumps) y permiten cosas como bucles, ejecución condicional de programas y funciones. Muchas instrucciones también cambian el estado de los dígitos en un registro de "banderas". Estas banderas pueden usarse para influir en cómo se comporta un programa, ya que a menudo indican el resultado de varias operaciones. Por ejemplo, una instrucción de "comparación" mira dos valores y ajusta una bandera según cuál sea mayor. Luego, una instrucción de salto puede usar esta bandera para decidir el flujo del programa.
Después de ejecutar la instrucción y guardar los datos, todo el proceso se repite con el siguiente ciclo de instrucción. Normalmente, se lee la siguiente instrucción en secuencia gracias al valor aumentado en el contador de programa. Si la instrucción completada fue un salto, el contador de programa se modifica para contener la dirección de la instrucción a la que se saltó, y el programa continúa normalmente. En CPU más complejas, se pueden leer, decodificar y ejecutar varias instrucciones al mismo tiempo. Esta descripción se llama "tubería RISC clásica", que es común en las CPU simples de muchos dispositivos electrónicos, a menudo llamadas microcontroladores.
Diseño y funcionamiento avanzado
Rango de números
La forma en que una CPU representa los números es una decisión de diseño que afecta cómo funciona el dispositivo. Casi todas las CPU modernas representan los números en forma binaria: cada dígito se representa con dos valores, como un voltaje "alto" o "bajo".

Relacionado con la representación numérica está el tamaño y la precisión de los números que una CPU puede manejar. En una CPU binaria, un bit es una posición significativa en los números. El número de bits que una CPU usa para representar números se llama a menudo "tamaño de la palabra" o "ancho de bits". Este número varía entre diferentes arquitecturas y a veces dentro de la misma CPU. Por ejemplo, una CPU de 8 bits maneja números que se pueden representar con ocho dígitos binarios. Cada dígito tiene dos valores posibles, y en combinación, los 8 bits pueden representar 28 o 256 números diferentes. El tamaño del número entero establece un límite en el rango de números que el software puede usar directamente con la CPU.
El rango del número entero también puede afectar la cantidad de ubicaciones de memoria que la CPU puede encontrar (direccionar). Por ejemplo, si una CPU binaria usa 32 bits para una dirección de memoria y cada dirección representa un octeto (8 bits), la cantidad máxima de memoria que la CPU puede direccionar es 232 octetos, es decir, 4 GB. Esta es una vista simplificada, ya que muchos diseños modernos usan métodos de direccionamiento más complejos para acceder a más memoria.
Un rango de números enteros más alto requiere más componentes y, por lo tanto, más complejidad, tamaño, uso de energía y, generalmente, costo. Por eso, no es raro ver microcontroladores de 4 y 8 bits en aplicaciones modernas, aunque existan CPU con rangos mucho más altos (de 16, 32, 64 e incluso 128 bits). Los microcontroladores más simples suelen ser más baratos, usan menos energía y disipan menos calor. Sin embargo, en aplicaciones de alto rendimiento, los beneficios del rango adicional (como más espacio de memoria) son más importantes. Para combinar las ventajas de diferentes anchos de bits, muchas CPU están diseñadas con anchos de bit distintos para diferentes unidades. Por ejemplo, el IBM System/370 usaba una CPU de 32 bits, pero con una precisión de 128 bits en sus unidades de coma flotante para mayor exactitud.
Frecuencia de reloj
La mayoría de las CPU funcionan de forma síncrona, es decir, se basan en una señal de tiempo llamada señal de reloj. Esta señal suele ser una onda cuadrada que se repite. Al calcular el tiempo máximo que las señales eléctricas pueden tardar en moverse por los circuitos de una CPU, los diseñadores eligen un período adecuado para la señal de reloj.
Este período debe ser más largo que el tiempo que necesita una señal para viajar en el peor de los casos. Al establecer el período del reloj, se puede diseñar toda la CPU para que los datos se muevan en los momentos exactos de la señal de reloj. Esto simplifica mucho el diseño de la CPU. Sin embargo, también significa que toda la CPU debe esperar a sus partes más lentas, incluso si algunas son mucho más rápidas. Esta limitación se ha compensado con métodos para aumentar el paralelismo de la CPU.
Las mejoras en la arquitectura no resuelven todos los problemas de las CPU síncronas. Por ejemplo, una señal de reloj también sufre retrasos. Las velocidades de reloj más altas en CPU cada vez más complejas hacen que sea más difícil mantener la señal de reloj sincronizada en toda la unidad. Esto ha llevado a que muchas CPU modernas necesiten varias señales de reloj idénticas. Otro problema importante con el aumento de la velocidad del reloj es la cantidad de calor que disipa la CPU. La señal de reloj cambia constantemente, lo que hace que muchos componentes cambien de estado, usen o no se estén usando. Un componente que cambia de estado usa más energía que uno estático. Por lo tanto, a medida que la velocidad del reloj aumenta, también lo hace la disipación de calor, lo que requiere soluciones de enfriamiento más efectivas.
Un método para evitar que los componentes innecesarios cambien de estado es el clock gating, que consiste en apagar la señal de reloj a esos componentes. Sin embargo, esto es difícil de implementar y no se usa comúnmente, excepto en diseños de muy bajo consumo. Un ejemplo notable es la CPU de la Xbox 360, que usa mucho clock gating para reducir el consumo de energía. Otro método es eliminar por completo la señal de reloj global. Aunque esto complica el diseño, los diseños asíncronos (o sin reloj) tienen ventajas en el consumo de energía y la disipación de calor. Aunque son poco comunes, se han construido CPU completas sin una señal de reloj global, como el AMULET (basado en la arquitectura ARM) y el MiniMIPS. Algunos diseños de CPU permiten que ciertas unidades sean asíncronas, como las ALUs, para mejorar el rendimiento.
Paralelismo

La descripción básica de la CPU que vimos antes se refiere a la forma más simple de CPU, llamada "subescalar". Este tipo de CPU procesa y ejecuta una sola instrucción con uno o dos datos a la vez.
Este proceso es ineficiente en las CPU subescalares. Como solo se ejecuta una instrucción a la vez, toda la CPU debe esperar a que esa instrucción termine antes de pasar a la siguiente. Esto hace que la CPU se "congele" en instrucciones que tardan más de un ciclo de reloj en completarse. Incluso añadir una segunda unidad de ejecución no mejora mucho el rendimiento. Este diseño, donde los recursos de ejecución de la CPU solo pueden trabajar con una instrucción a la vez, solo puede alcanzar un rendimiento "escalar" (una instrucción por ciclo de reloj). Sin embargo, el rendimiento casi siempre es subescalar (menos de una instrucción por ciclo).
Los intentos de lograr un rendimiento escalar o mejor han llevado a diferentes métodos de diseño que hacen que la CPU se comporte de forma menos lineal y más en paralelo. Cuando hablamos de paralelismo en las CPU, se usan dos términos para clasificar estas técnicas:
- Paralelismo a nivel de instrucción (ILP): Busca aumentar la velocidad a la que se ejecutan las instrucciones dentro de una CPU, es decir, usar mejor los recursos de ejecución del chip.
- Paralelismo a nivel de hilo de ejecución (TLP): Busca aumentar el número de hilos (programas individuales) que una CPU puede ejecutar al mismo tiempo.
Cada método se implementa de forma diferente y produce distintos aumentos en el rendimiento de la CPU.
ILP: Segmentación y arquitectura superescalar

Uno de los métodos más sencillos para aumentar el paralelismo es empezar los primeros pasos de leer y decodificar una instrucción antes de que la instrucción anterior haya terminado de ejecutarse. Esta es la forma más simple de una técnica llamada segmentación (instruction pipelining en inglés), y se usa en casi todas las CPU modernas. Al dividir el proceso de ejecución en etapas separadas, la tubería permite que se ejecuten varias instrucciones al mismo tiempo. Esto se puede comparar con una línea de ensamblaje, donde una instrucción se completa un poco más en cada etapa hasta que sale de la tubería.
Sin embargo, la tubería puede causar un problema: a veces, el resultado de una operación anterior es necesario para completar la siguiente. Esto se llama "conflicto de dependencia de datos". Para solucionarlo, se debe tener cuidado de comprobar estas condiciones y, si ocurren, retrasar una parte de la tubería de instrucciones. Esto requiere circuitos adicionales, por lo que los procesadores con tubería son más complejos que los subescalares, pero no mucho. Un procesador con tubería puede llegar a ser casi completamente escalar, solo limitado por las paradas de la tubería (cuando una instrucción tarda más de un ciclo de reloj en una etapa).

Una mejora adicional de la idea de la tubería de instrucciones llevó al desarrollo de un método que reduce aún más el tiempo de inactividad de los componentes de la CPU. Los diseños que se consideran superescalares incluyen una tubería de instrucciones larga y varias unidades de ejecución idénticas. En una tubería superescalar, se leen varias instrucciones y se envían a un "despachador". El despachador decide si las instrucciones se pueden ejecutar en paralelo (al mismo tiempo). Si es así, las envía a las unidades de ejecución disponibles, lo que permite que varias instrucciones se ejecuten simultáneamente. En general, cuantas más instrucciones pueda enviar una CPU superescalar a las unidades de ejecución, más instrucciones se completarán en un ciclo dado.
La mayor dificultad al diseñar una CPU superescalar es crear un despachador eficiente. El despachador debe ser capaz de determinar rápida y correctamente si las instrucciones pueden ejecutarse en paralelo, y enviarlas de manera que mantenga ocupadas tantas unidades de ejecución como sea posible. Esto requiere que la tubería de instrucciones se llene lo más a menudo posible y aumenta la necesidad de grandes cantidades de caché de CPU en las arquitecturas superescalares. También se usan técnicas para evitar problemas, como la predicción de bifurcación, la ejecución especulativa y la ejecución fuera de orden, que son cruciales para mantener un alto rendimiento. Al intentar predecir qué camino tomará una instrucción condicional, la CPU puede minimizar las veces que todo el canal debe esperar. La ejecución especulativa a menudo mejora el rendimiento al ejecutar partes de código que quizás no sean necesarias después de una operación condicional. La ejecución fuera de orden cambia el orden en que se ejecutan las instrucciones para reducir los retrasos por dependencias de datos.
Cuando una parte de la CPU es superescalar y otra no, la parte no superescalar afecta el rendimiento. El Intel Pentium original (P5) tenía dos ALUs superescalares que podían aceptar una instrucción por ciclo de reloj, pero su FPU (unidad de coma flotante) no. Así, el P5 era superescalar en la parte de números enteros, pero no en la de números de coma flotante. El sucesor de la arquitectura Pentium de Intel, el P6, añadió capacidades superescalares a sus funciones de coma flotante, lo que mejoró mucho el rendimiento de este tipo de instrucciones.
Tanto el diseño superescalar como la segmentación simple aumentan el ILP de una CPU al permitir que un solo procesador complete la ejecución de instrucciones a una velocidad superior a una instrucción por ciclo (IPC). La mayoría de los diseños de CPU modernos son al menos algo superescalares, y en la última década, casi todos los diseños de CPU de propósito general lo son. En los últimos años, parte del enfoque en el diseño de ordenadores de alto ILP se ha trasladado del hardware de la CPU a su interfaz de software, o ISA. La estrategia very long instruction word o VLIW, hace que parte del ILP sea directamente implícito por el software, reduciendo el trabajo que la CPU debe hacer y simplificando el diseño.
Paralelismo a nivel de hilos
Otra estrategia para mejorar el rendimiento es ejecutar varios programas o hilos al mismo tiempo. Esta área se conoce como computación paralela.
Una tecnología usada para esto es el multiprocesamiento (MP). El inicio de esta tecnología se conoce como multiprocesamiento simétrico (SMP), donde un pequeño número de CPU comparten una vista coherente de su sistema de memoria. En este esquema, cada CPU tiene hardware adicional para mantener una vista actualizada de la memoria. Para evitar datos antiguos, las CPU pueden cooperar en el mismo programa y los programas pueden moverse de una CPU a otra. Para aumentar el número de CPU que cooperan más allá de unas pocas, se introdujeron en 1990 esquemas como el acceso no uniforme a memoria (NUMA) y los protocolos de coherencia basados en directorios. Los sistemas SMP se limitan a un pequeño número de CPU, mientras que los sistemas NUMA se han construido con miles de procesadores. Inicialmente, el multiprocesamiento se construía usando múltiples CPU separadas y tarjetas para conectarlas. Cuando los procesadores y su interconexión se implementan en un solo chip de silicio, la tecnología se conoce como procesador multinúcleo.
Más tarde, se vio que un solo programa podía tener varias partes (hilos o funciones) que podían ejecutarse por separado o en paralelo. Algunos de los primeros ejemplos de esta tecnología implementaban el procesamiento de entrada/salida, como el acceso directo a memoria, como un hilo separado del hilo de cálculo. En la década de 1970, se introdujo un enfoque más general, cuando se diseñaron sistemas para ejecutar múltiples hilos de cálculo en paralelo. Esta tecnología se conoce como multihilo (MT).
Este enfoque se considera más rentable que el multiprocesamiento, ya que solo se replican unos pocos componentes dentro de una CPU para soportar MT, a diferencia de replicar toda la CPU en el caso de MP. En MT, las unidades de ejecución y el sistema de memoria, incluyendo los cachés, son compartidos entre varios hilos. La desventaja de MT es que el soporte de hardware para multihilo es más visible para el software que el de MP, por lo que el software de supervisión, como los sistemas operativos, tienen que hacer más cambios para soportar MT. Un tipo de MT implementado es el multihilo por bloques, donde un hilo se ejecuta hasta que se detiene esperando datos de la memoria externa. En este esquema, la CPU cambia rápidamente a otro hilo que está listo para funcionar, a menudo en un solo ciclo de reloj de la CPU, como en la tecnología UltraSPARC. Otro tipo de MT se llama multihilo simultáneo, donde las instrucciones de múltiples hilos se ejecutan en paralelo dentro de un ciclo de reloj de la CPU.
Paralelismo de datos
Un tipo de CPU menos común pero cada vez más importante (y de la computación en general) trabaja con vectores. Los procesadores que hemos visto hasta ahora se llaman "escalares". Como su nombre indica, los procesadores vectoriales manejan múltiples datos con una sola instrucción. Esto contrasta con los procesadores escalares, que manejan un dato por cada instrucción. Estos dos esquemas se conocen como SISD (single instruction, single data – una instrucción, un dato) y SIMD (single instruction, multiple data – una instrucción, múltiples datos). La gran utilidad de crear CPU que manejen vectores de datos está en optimizar tareas que requieren la misma operación (por ejemplo, una suma o un producto escalar) en un gran conjunto de datos. Algunos ejemplos clásicos de estas tareas son las aplicaciones multimedia (imágenes, vídeo y sonido), así como muchos tipos de tareas científicas y de ingeniería. Mientras que una CPU escalar debe completar todo el proceso de leer, decodificar y ejecutar cada instrucción y valor en un conjunto de datos, una CPU vectorial puede realizar una operación simple en un conjunto de datos comparativamente grande con una sola instrucción. Por supuesto, esto solo es posible cuando la aplicación necesita muchos pasos que apliquen una operación a un gran conjunto de datos.
La mayoría de las primeras CPU vectoriales, como el Cray-1, se usaban casi exclusivamente en investigación científica y criptografía. Sin embargo, a medida que el contenido multimedia se volvió digital, la necesidad de alguna forma de SIMD en las CPU de propósito general se hizo importante. Poco después de que las unidades de coma flotante se volvieran comunes en los procesadores de uso general, también comenzaron a aparecer especificaciones e implementaciones de unidades de ejecución SIMD para las CPU de uso general. Algunas de estas primeras especificaciones SIMD, como el MMX de Intel, eran solo para números enteros. Esto fue un impedimento para algunos desarrolladores de software, ya que muchas aplicaciones que se beneficiaban del SIMD trabajaban principalmente con números de coma flotante. Poco a poco, estos diseños iniciales se mejoraron y se convirtieron en las especificaciones SIMD modernas, que generalmente están asociadas a un ISA. Algunos ejemplos modernos notables son el SSE de Intel y el AltiVec relacionado con el PowerPC (también conocido como VMX).
Rendimiento de un procesador

El "rendimiento" o la velocidad de un procesador depende de muchos factores. Entre ellos, la velocidad del reloj (medida en hertz) y las instrucciones por ciclo de reloj (IPC). Juntos, estos factores determinan las instrucciones por segundo (IPS) que la CPU puede procesar.
Muchos informes de valores IPS muestran tasas de ejecución "pico" en secuencias de instrucciones artificiales, pero las tareas reales combinan diferentes instrucciones y aplicaciones, algunas de las cuales tardan más en ejecutarse. El rendimiento de la jerarquía de memoria también afecta mucho al rendimiento del procesador, algo que a menudo no se tiene en cuenta en los cálculos de MIPS. Debido a estos problemas, se han desarrollado pruebas estandarizadas, como SPECint, a menudo llamadas "puntos de referencia", para intentar medir el rendimiento real en aplicaciones de uso diario.
El rendimiento de procesamiento de los ordenadores aumenta al usar procesadores multinúcleo. Esto significa conectar dos o más procesadores individuales (llamados núcleos) en un solo circuito integrado. Idealmente, un procesador de doble núcleo sería casi el doble de potente que uno de un solo núcleo. En la práctica, la mejora de rendimiento es menor, alrededor del 50%, debido a que los algoritmos de software no son perfectos. Aumentar el número de núcleos en un procesador (es decir, doble núcleo, cuádruple núcleo, etc.) aumenta la cantidad de trabajo que puede manejar. Esto significa que el procesador puede manejar muchos eventos y tareas al mismo tiempo. Estos núcleos pueden verse como diferentes pisos en una planta de procesamiento, donde cada piso maneja una tarea diferente. A veces, estos núcleos manejan las mismas tareas que los núcleos adyacentes si un solo núcleo no es suficiente para la información.
Debido a las capacidades específicas de las CPU modernas, como HyperThreading y Uncore, que implican compartir recursos reales de la CPU para lograr una mayor utilización, supervisar los niveles de rendimiento y la utilización del hardware se ha vuelto más complejo. Como respuesta, algunas CPU implementan lógica de hardware adicional que controla la utilización real de las diversas partes de una CPU y proporciona contadores accesibles al software; un ejemplo es la tecnología Performance Counter Monitor de Intel.
Galería de imágenes
-

Vista superior de una CPU Intel 80486DX2 en un paquete PGA de cerámica.
-

Vista posterior de una Intel 80486DX2.
-

Procesador moderno con 8 núcleos y 16 hilos de procesamiento.
-

El ENIAC, una de los primeros ordenadores de programas almacenados electrónicamente.
-

CPU, memoria de núcleo e interfaz de bus externo de un MSI PDP-8/I. Hecho de circuitos integrados de mediana escala.
-

Oblea de un microprocesador Intel 80486DX2 (tamaño: 12×6,75 mm) en su empaquetado.
-

CPU Intel Core i5 en una placa base del ordenador portátil Vaio serie E (a la derecha, debajo del tubo termosifón bifásico.
-

Diagrama mostrando como es decodificada una instrucción del MIPS32. (MIPS Technologies 2005)
-
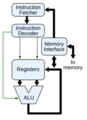
Diagrama de bloques de un CPU simple.
-

Microprocesador MOS 6502 en un dual in-line package (encapsulado en doble línea), un diseño extremadamente popular de 8 bits.
-
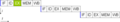
Modelo de una CPU subescalar. Note que toma quince ciclos para terminar tres instrucciones.
-

Tubería básica de cinco etapas. En el mejor de los casos, esta tubería puede sostener un ratio de completado de una instrucción por ciclo.
-
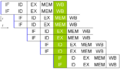
Segmentación superescalar simple. Al leer y despachar dos instrucciones a la vez, un máximo de dos instrucciones por ciclo pueden ser completadas.
-

Intel Core i9 12900k Verkaufsverpackung
Véase también
 En inglés: Central processing unit Facts for Kids
En inglés: Central processing unit Facts for Kids
