
Red neuronal artificial para niños

En el aprendizaje automático, una red neuronal artificial (abreviada RNA o RN) es un modelo inspirado en cómo funcionan las redes de células nerviosas en los cerebros de los animales. Una RNA está formada por unidades o nodos conectados, llamados neuronas artificiales. Estas neuronas se conectan entre sí mediante "enlaces", que son como las sinapsis del cerebro. Cada neurona artificial recibe "señales" de otras neuronas conectadas. Luego, procesa estas señales y envía una nueva señal a otras neuronas. La "señal" es un número, y la salida de cada neurona se calcula usando una fórmula especial que suma sus entradas. La fuerza de la señal en cada conexión se ajusta durante el proceso de aprendizaje.
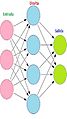
Normalmente, las neuronas se organizan en grupos llamados capas. Las diferentes capas pueden transformar la información de distintas maneras. Las señales viajan desde la primera capa (la capa de entrada) hasta la última capa (la capa de salida). En el camino, pueden pasar por varias capas intermedias, llamadas capas ocultas. Una red se considera "profunda" si tiene al menos dos capas ocultas.
Contenido
- ¿Cómo aprenden las redes neuronales artificiales?
- Breve historia de las redes neuronales
- ¿Cómo funcionan los modelos de redes neuronales?
- Algoritmos de aprendizaje
- Aplicaciones de las redes neuronales artificiales
- Potencia de cálculo
- Clases y tipos de RNA
- Ejemplos de uso
- Galería de imágenes
- Herramientas de software
- Véase también
¿Cómo aprenden las redes neuronales artificiales?
Las redes neuronales aprenden ajustando sus conexiones para reducir la diferencia entre lo que predicen y lo que deberían predecir. Esto se hace optimizando los parámetros de la red. Métodos como la retropropagación se usan para ajustar estos parámetros. Durante el entrenamiento, las RNA aprenden de datos de ejemplo, cambiando sus conexiones para minimizar un "error" definido.
Las redes neuronales artificiales se usan para muchas tareas. Por ejemplo, pueden predecir cosas, controlar sistemas o resolver problemas de inteligencia artificial. Pueden aprender de la experiencia y encontrar patrones en información compleja. Son muy buenas en áreas donde es difícil escribir reglas de programación tradicionales. Para aprender, intentan reducir una "función de pérdida" que mide qué tan bien lo están haciendo. Los valores de las conexiones se actualizan para disminuir esta función de pérdida. Este proceso se llama propagación hacia atrás.
Las redes neuronales modernas pueden tener desde miles hasta millones de neuronas artificiales.
Nuevas investigaciones sobre el cerebro inspiran la creación de nuevos tipos de redes neuronales. Algunos estudios exploran conexiones que van más allá de las neuronas cercanas. Otros investigan cómo las señales se propagan a lo largo del tiempo, como en el aprendizaje profundo.
Las redes neuronales se han usado para resolver tareas difíciles. Por ejemplo, la visión por computadora y el reconocimiento de voz son complicados con la programación normal. Históricamente, el uso de redes neuronales marcó un cambio. Se pasó de sistemas basados en reglas a sistemas que aprenden de los datos.
Breve historia de las redes neuronales
Warren McCulloch y Walter Pitts (1943) crearon un modelo matemático para las redes neuronales. Este modelo, llamado lógica umbral, usaba matemáticas y algoritmos. Su trabajo llevó a dos caminos de investigación: uno se centró en cómo funciona el cerebro biológico, y el otro en usar redes neuronales para la inteligencia artificial.
Primeros pasos y el aprendizaje de Hebb
A finales de la década de 1940, el psicólogo Donald Hebb propuso una idea sobre cómo aprenden las neuronas. Esta idea, conocida como aprendizaje de Hebb, dice que las conexiones entre neuronas se fortalecen cuando se activan juntas. Este fue uno de los primeros modelos de aprendizaje a largo plazo.
Investigadores como Farley y Wesley A. Clark (1954) usaron las primeras computadoras para simular redes basadas en la idea de Hebb. Otros, como Rochester, Holland, Habit y Duda (1956), también hicieron simulaciones.
Frank Rosenblatt (1958) creó el perceptrón. Este era un algoritmo para reconocer patrones que usaba una red de computadora de dos capas. Sin embargo, el perceptrón básico no podía resolver problemas más complejos, como el circuito "o-exclusivo". Esto cambió con la creación del algoritmo de propagación hacia atrás por Paul Werbos (1975).
En 1959, dos científicos que ganaron el Premio Nobel, David H. Hubel y Torsten Wiesel, propusieron un modelo biológico. Se basaron en su descubrimiento de dos tipos de células en la corteza visual del cerebro.
El primer informe sobre redes con múltiples capas funcionales fue publicado en 1965 por Ivakhnenko y Lapa.
La investigación en redes neuronales se detuvo un poco después de un estudio de Marvin Minsky y Seymour Papert (1969). Ellos señalaron dos problemas: los perceptrones básicos no podían resolver el problema "o-exclusivo", y las computadoras de la época no eran lo suficientemente potentes para manejar redes neuronales grandes.
La propagación hacia atrás y el resurgimiento
Un avance muy importante fue el algoritmo de propagación hacia atrás (en inglés, backpropagation). Este algoritmo resolvió el problema "o-exclusivo" y permitió entrenar redes neuronales con muchas capas de forma más rápida (Werbos 1975). La propagación hacia atrás usa la diferencia entre el resultado obtenido y el resultado deseado para ajustar la "fuerza" de las conexiones entre las neuronas artificiales.
A mediados de los años 80, la idea del "procesamiento distribuido en paralelo" se hizo popular, conocida como conexionismo. El libro de David E. Rumelhart y James McClelland (1986) explicó cómo usar el conexionismo en computadoras para simular procesos neuronales.
Las redes neuronales, usadas en la inteligencia artificial, se han visto como modelos simplificados de cómo funciona el cerebro. Aunque su relación con la biología del cerebro se sigue debatiendo, no está claro hasta qué punto las redes neuronales artificiales imitan el funcionamiento cerebral.
Otros métodos de aprendizaje automático, como las Máquinas de vectores de soporte, ganaron popularidad. Sin embargo, las redes neuronales han transformado algunos campos, como la predicción de estructuras de proteínas.
En 1992, se introdujo el "max-pooling". Esta técnica ayuda al reconocimiento de objetos tridimensionales. En 2010, el uso de max-pooling con GPUs aceleró el entrenamiento y mejoró el rendimiento.
El problema del desvanecimiento del gradiente afecta a las redes neuronales con muchas capas. Hace que los errores disminuyan mucho al propagarse, dificultando el ajuste de las conexiones. Para solucionar esto, Schmidhuber (1992) propuso entrenar las redes capa por capa.
A medida que se resolvieron los desafíos de entrenar redes neuronales profundas, estas se usaron a gran escala. Especialmente en problemas de procesamiento de imágenes y reconocimiento visual. Esto se conoce como "aprendizaje profundo".
¿Cómo funcionan los modelos de redes neuronales?
Los modelos de redes neuronales en la inteligencia artificial se refieren a las redes neuronales artificiales (RNA). Son modelos matemáticos que definen una función para transformar datos. A veces, estos modelos también están asociados con un algoritmo de aprendizaje específico.
La función de una red
La palabra red en "red neuronal artificial" se refiere a cómo se conectan las neuronas en las diferentes capas. Un sistema simple puede tener tres capas: una de entrada, una intermedia y una de salida. Los sistemas más complejos tienen más capas. Las conexiones entre neuronas guardan "pesos" que ajustan los datos en los cálculos.
Una RNA se define por tres cosas principales:
1. El patrón de conexión entre las capas de neuronas. 2. El proceso de aprendizaje para actualizar los "pesos" de las conexiones. 3. La función de activación, que convierte las entradas de una neurona en su salida.
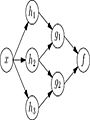
Matemáticamente, la función de una neurona se define como una combinación de otras funciones. Esto se representa como una red, con flechas que muestran las dependencias entre variables. Un tipo común es la "suma ponderada no lineal".

Las redes como la anterior se llaman "de alimentación hacia adelante" porque la información fluye en una sola dirección. Las redes con "ciclos" se llaman "recurrentes".
El aprendizaje
Lo más interesante de las redes neuronales es su capacidad de aprender. Dada una tarea, el aprendizaje consiste en usar ejemplos para encontrar la mejor función que resuelva esa tarea.
Esto implica definir una "función de costo". Esta función mide qué tan lejos está una solución de la solución ideal. Los algoritmos de aprendizaje buscan la función que tenga el costo más bajo posible.
Si la solución depende de datos, el costo debe ser una "función de las observaciones". A menudo, el costo se calcula usando una muestra de los datos, no todos los datos posibles.
Cuando hay muchos datos, se usa el "aprendizaje automático en línea". Aquí, el costo se reduce poco a poco a medida que se ve cada nuevo ejemplo.
¿Cómo se elige una función de costo?
Aunque se puede definir cualquier función de costo, a menudo se usa una específica. Esto puede ser porque tiene propiedades útiles o porque surge naturalmente del problema. Al final, la función de costo dependerá de la tarea que se quiera resolver.
Formas de aprender
Hay tres formas principales en que las redes neuronales pueden aprender:
Aprendizaje supervisado
En el aprendizaje supervisado, se le dan a la red ejemplos de pares de entrada y salida. El objetivo es que la red aprenda a relacionar las entradas con las salidas. La función de costo mide qué tan bien la red predice las salidas correctas.
Un costo común es el error cuadrático medio. Este intenta minimizar la diferencia entre lo que la red produce y el valor correcto. Cuando se minimiza este costo usando el descenso de gradiente en redes como los perceptrones multicapa, se obtiene el famoso algoritmo de propagación hacia atrás.
Tareas como el reconocimiento de patrones (clasificación) y la predicción (aproximación de funciones) usan el aprendizaje supervisado. También se aplica a datos secuenciales, como el reconocimiento del habla o de la escritura. Es como aprender con un "maestro" que da retroalimentación constante.
Aprendizaje no supervisado
En el aprendizaje no supervisado, la red recibe datos sin etiquetas de salida. La función de costo se minimiza para encontrar patrones o estructuras ocultas en los datos.
La función de costo depende de la tarea y de lo que se quiera modelar. Por ejemplo, en la compresión de datos, podría estar relacionada con la información compartida entre la entrada y la salida.
Tareas como el agrupamiento (clustering), la compresión de datos y el filtrado de spam usan el aprendizaje no supervisado.
Aprendizaje por refuerzo
En el aprendizaje por refuerzo, la red (o "agente") aprende interactuando con un entorno. El agente realiza una acción, y el entorno le da una observación y un "costo" (o recompensa). El objetivo es que el agente aprenda a elegir acciones que minimicen el costo a largo plazo.
Las RNA se usan a menudo en el aprendizaje por refuerzo. La programación dinámica se ha combinado con las RNA para resolver problemas complejos, como el enrutamiento de vehículos o la gestión de recursos.
Tareas como el control de sistemas, los juegos y otras tareas secuenciales usan el aprendizaje por refuerzo.
Tipos de entrada
Las RNA también se clasifican según el tipo de información que pueden procesar:
- Redes analógicas: Procesan datos de entrada con valores continuos (como números con decimales). Ejemplos son las redes Hopfield y Kohonen.
- Redes discretas: Procesan datos de entrada con valores específicos, como los valores lógicos (verdadero/falso). Ejemplos son las máquinas de Boltzmann y Cauchy.
Algoritmos de aprendizaje
Entrenar una red neuronal significa elegir el mejor modelo que minimice el costo. Hay muchos algoritmos para esto, la mayoría basados en la teoría de optimización.
La mayoría de los algoritmos usan alguna forma de descenso de gradiente, con la propagación hacia atrás para calcular los "gradientes" (la dirección en la que el costo disminuye). Esto se hace ajustando los parámetros de la red en la dirección del gradiente.
Otros métodos para entrenar redes neuronales incluyen métodos evolutivos, recocido simulado y optimización por enjambre de partículas.
Ventajas de usar redes neuronales artificiales
Una gran ventaja de las RNA es que pueden "aprender" de los datos observados para aproximar cualquier función. Sin embargo, usarlas bien requiere entender cómo funcionan.
- La complejidad del modelo debe ser adecuada para los datos. Modelos demasiado complejos pueden causar problemas.
- Hay muchas opciones de algoritmos de aprendizaje. Encontrar el mejor para datos nuevos requiere experimentación.
- Si se eligen bien el modelo, la función de costo y el algoritmo, la RNA puede ser muy robusta.
- Las RNA son buenas para el aprendizaje en línea y para trabajar con grandes cantidades de datos. Su estructura permite implementaciones rápidas y paralelas en hardware.
Aplicaciones de las redes neuronales artificiales
Las RNA son muy útiles cuando no se tiene un modelo matemático claro para un problema, pero sí se tienen muchos ejemplos de datos. También son resistentes al "ruido" (datos imperfectos) y a fallos en partes de la red. Además, pueden trabajar en paralelo.
Se usan para problemas de clasificación y reconocimiento de patrones en voz, imágenes o señales. También se han usado para detectar fraudes, predecir el mercado financiero o el clima.
Son útiles cuando no hay algoritmos matemáticos precisos o son demasiado complejos. Por ejemplo, la red de Kohonen se ha aplicado con éxito al famoso problema del viajante, que es muy difícil de resolver con algoritmos tradicionales.
Otro uso es en robótica evolutiva, donde se combinan con algoritmos genéticos para crear controladores para robots.
Ejemplos de aplicaciones en la vida real
Las tareas en las que se aplican las redes neuronales artificiales suelen caer en estas categorías:
- Aproximación de funciones o análisis de regresión, como la predicción de series de tiempo.
- Clasificación, incluyendo el reconocimiento de patrones y la toma de decisiones.
- Procesamiento de datos, como el filtrado, el agrupamiento y la compresión.
- Robótica, incluyendo el control de brazos robóticos y prótesis.
- Ingeniería de control, como el control numérico por computadora.
Otras áreas de aplicación incluyen:
- Identificación de sistemas y control (control de vehículos, predicción de trayectorias).
- Química cuántica.
- Juegos y toma de decisiones (ajedrez, póquer).
- Reconocimiento de patrones (sistemas de radar, reconocimiento facial, clasificación de señales).
- Diagnóstico médico.
- Aplicaciones económico-financieras (sistemas automatizados para el comercio).
- Minería de datos (descubrimiento de conocimiento en bases de datos).
- Traducción automática.
- Diferenciar entre informes deseados y no deseados en redes sociales.
- Prevención de spam en correos electrónicos.
Las redes neuronales artificiales también se han usado para ayudar en el diagnóstico de varios tipos de cáncer. Por ejemplo, un sistema híbrido basado en RNA mejoró la precisión y velocidad en el diagnóstico de cáncer de pulmón. También se han usado para diagnosticar cáncer de próstata y colorrectal, prediciendo resultados de pacientes con más precisión que los métodos clínicos actuales.
Redes neuronales y neurociencia
La neurociencia computacional estudia y modela los sistemas neuronales biológicos. Busca entender cómo funcionan los sistemas biológicos creando modelos. Para esto, los neurocientíficos intentan conectar los procesos biológicos observados con modelos de redes neuronales biológicas y la teoría del aprendizaje.
Tipos de modelos Se usan muchos modelos, que varían en su nivel de detalle. Van desde modelos del comportamiento de neuronas individuales hasta modelos de cómo surge el comportamiento de sistemas neuronales completos.
Redes con memoria La combinación de memoria externa con redes neuronales artificiales tiene una larga historia. Por ejemplo, en la memoria distribuida dispersa, los patrones codificados por las redes neuronales se usan como direcciones de memoria.
Más recientemente, el aprendizaje profundo ha sido útil en el "hashing semántico". Aquí, los documentos se asignan a direcciones de memoria de tal manera que los documentos con significados similares están en direcciones cercanas.
Las "redes de memoria" son otra extensión que incorporan memoria a largo plazo. Estas se han usado en sistemas de respuesta a preguntas, donde la memoria a largo plazo actúa como una base de conocimientos.
Las Máquinas de Turing neuronales, desarrolladas por Google DeepMind, combinan redes neuronales profundas con recursos de memoria externos. El sistema es similar a una máquina de Turing y puede aprender algoritmos simples a partir de ejemplos.
Las "computadoras neuronales diferenciables" (DNC), también de DeepMind, son una extensión de las máquinas de Turing neuronales. Han superado a otros sistemas en tareas de procesamiento de secuencias.
Software de red neuronal El software de red neuronal se usa para simular, investigar, desarrollar y aplicar redes neuronales artificiales y biológicas.
Tipos de redes neuronales artificiales Los tipos de redes neuronales artificiales varían mucho. Pueden tener desde una o dos capas con lógica simple hasta muchos bucles complejos con retroalimentación. Generalmente, usan algoritmos para controlar sus funciones. La mayoría de los sistemas usan "pesos" para cambiar el rendimiento y las conexiones. Las RNA pueden aprender de "maestros" externos o incluso autoaprender.
Potencia de cálculo
El perceptrón multicapa puede aproximar cualquier función, según el teorema de aproximación universal. Sin embargo, este teorema no dice cuántas neuronas se necesitan ni cómo configurarlas.
El trabajo de Hava Siegelmann y Eduardo D. Sontag demostró que una arquitectura recurrente específica puede tener la misma potencia que una máquina universal de Turing usando un número finito de neuronas y conexiones estándar.
Capacidad Los modelos de redes neuronales artificiales tienen una "capacidad", que es su habilidad para modelar cualquier función. Se relaciona con la cantidad de información que pueden almacenar y su complejidad.
Convergencia No se puede decir mucho en general sobre la "convergencia" (si el aprendizaje llegará a un punto estable), ya que depende de muchos factores. Puede haber muchos mínimos locales (puntos donde el costo es bajo, pero no el más bajo). Además, el método de optimización puede no garantizar la convergencia. Para muchos datos, algunos métodos se vuelven poco prácticos.
Generalización y estadísticas En aplicaciones donde el objetivo es que el sistema funcione bien con ejemplos que no ha visto, surge el problema del "sobreentrenamiento". Esto ocurre cuando la red es demasiado compleja para los datos. Hay dos formas de evitarlo: 1. Usar técnicas como la validación cruzada para detectar el sobreentrenamiento y ajustar los parámetros. 2. Usar algún tipo de "regularización". Esto ayuda a que el modelo sea más simple y generalice mejor.
Las redes neuronales supervisadas que usan el error cuadrático medio (MSE) pueden usar métodos estadísticos para determinar la confianza del modelo. El MSE en un conjunto de validación puede estimar la varianza, lo que permite calcular el intervalo de confianza de la salida de la red.

Al usar una función de activación softmax en la capa de salida, las salidas se pueden interpretar como probabilidades. Esto es muy útil en la clasificación, ya que da una medida de la seguridad en las clasificaciones.
Clases y tipos de RNA
- Red Neuronal Dinámica
- Red Neuronal Feedforward (FNN)
- Red Neuronal Recurrente (RNN)
- Red de Hopfield
- Máquina de Boltzmann
- Redes recurrentes simples
- Red estatal de eco
- Memoria de Largo a Corto Plazo (LSTM)
- RNN Bidireccional
- RNN Jerárquica
- Redes Neuronales Estocásticas
- Mapas Autoorganizados de Kohonen
- Autoencoder
- Red Neuronal Probabilística (PNN)
- Red Neuronal de Retardo de Tiempo (TDNN)
- Red de Realimentación Reguladora (RFNN)
- Red Neuronal Estática
- Neocognitron
- Neurona de McCulloch-Pitts
- Red de Función de Base Radial (RBF)
- Aprendizaje de Cuantificación Vectorial
- Perceptrón
- Modelo Adaline
- Red Neuronal de Convolución (CNN)
- Redes Neuronales Modulares
- Comité de Máquinas (COM)
- Red Neuronal Asociativa (ASNN)
- Red de Memoria
- Google / Google DeepMind
- Facebook / MemNN
- Memoria asociativa holográfica
- Memoria Asociativa One-shot
- Máquina de Turing neuronal
- Teoría de la Resonancia Adaptativa (ART)
- Memoria Temporal Jerárquica
- Otros tipos de redes
- Redes Neuronales Formadas Instantáneamente (ITNN)
- Red Neuronal de Impulsos (SNN)
- Redes Neuronales Codificadas por Impulsos (PCNN)
- Redes Neuronales en Cascada
- Redes Neuro-Fuzzy
- Gas Neural Creciente (GNG)
- Redes Productoras de Patrones de Composición
- Red de contrapropagación
- Red neuronal oscilante
- Red Neuronal Híbrida
- Red neuronal física
- Red neuronal óptica
- Red neuronal residual
- Red Neuronal Gráfica (GNN)
Ejemplos de uso
Quake II Neuralbot
Un bot es un programa que simula a un jugador humano. El Neuralbot es un bot para el juego Quake II que usa una red neuronal artificial para decidir cómo actuar y un algoritmo genético para aprender. Es fácil ver cómo evoluciona. Más información aquí [1]
Clasificador de Proteínas
Este es un programa que combina varias técnicas para clasificar familias de proteínas. Un método posible es usar métricas adaptativas, como los mapas autoorganizados y los algoritmos genéticos.
El problema de clasificar proteínas basándose en sus aminoácidos se puede resumir en:
- Identificar grupos de proteínas con características comunes.
- Entender por qué las proteínas se agrupan de cierta manera.
- Evitar ideas preconcebidas al clasificar, para que la clasificación sea lo más objetiva posible.
Las RNA se han aplicado a muchos problemas complejos de la vida real. Su mayor ventaja es resolver problemas que son muy difíciles para la tecnología actual, especialmente aquellos que no tienen una solución algorítmica clara o cuya solución es demasiado complicada de encontrar.
En general, como son parecidas al cerebro humano, las RNA son buenas para resolver problemas que los humanos pueden resolver pero las computadoras no. Esto incluye el reconocimiento de patrones y la predicción del tiempo. A diferencia de los humanos, las redes neuronales no se cansan ni se ven afectadas por el estado de ánimo.
Se conocen cinco aplicaciones tecnológicas comunes:
- Reconocimiento de textos escritos a mano.
- Reconocimiento del habla.
- Simulación de centrales de producción de energía.
- Detección de explosivos.
- Identificación de objetivos en radares.
Galería de imágenes
-
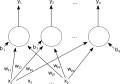
Una sola capa de red neuronal artificial feedforward. Flechas procedentes de x2 se omiten para mayor claridad. Hay P entradas a esta red y salidas q. En este sistema, el valor de la salida q-ésima, y_qse calcula como y_q=K*(∑(x_i*w_iq )-b_q)
-
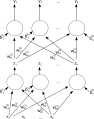
Una red neuronal artificial feedforward de dos capas.
-
Una red artificial de alimentación directa de una sola capa neuronal con 4 entradas, 6 ocultos y 2 salidas. Las salidas de estado y dirección determinada posición de la rueda basan los valores de control
-
Una red artificial de alimentación directa de dos capas neuronales con 8 entradas, 2x8 ocultos y 2 salidas. Estado determinada posición, dirección y otro ambiente de valores. Los valores de control basados en salidas empujador.
-
Indefinido
-
Indefinido





Herramientas de software
Existen muchas herramientas de software para implementar redes neuronales artificiales, tanto gratuitas como comerciales:
Véase también
 En inglés:
En inglés: 