
Código genético para niños
El código genético es como un manual de instrucciones que usan nuestras células para construir las proteínas. Imagina que es un idioma secreto que traduce la información guardada en el ARN (Ácido Ribonucleico) en una secuencia de aminoácidos, que son los "ladrillos" con los que se forman las proteínas.
Este código es casi el mismo en todos los seres vivos y en los virus. Esto nos hace pensar que todos venimos de un mismo origen en la Tierra.
El código funciona así: cada grupo de tres "letras" (llamadas nucleótidos) en el ARN se llama codón. Cada codón le dice a la célula qué aminoácido debe añadir a la proteína que se está formando.
Las "letras" del material genético son cuatro bases nitrogenadas:
- En el ADN (Ácido Desoxirribonucleico) son: adenina (A), timina (T), guanina (G) y citosina (C).
- En el ARN son: adenina (A), uracilo (U), guanina (G) y citosina (C).
Como hay cuatro letras y los codones tienen tres letras, hay 64 combinaciones posibles (4x4x4 = 64). De estos 64 codones:
- 61 codifican para los 20 aminoácidos diferentes.
- Uno de ellos (AUG) es especial porque no solo codifica un aminoácido (metionina), sino que también es la señal de "inicio" para construir una proteína.
- Los otros tres (UAA, UAG, UGA) son señales de "parada", que le dicen a la célula que la proteína ya está completa.
La secuencia de estos codones es lo que determina el orden de los aminoácidos en una proteína, y ese orden es clave para que la proteína tenga su forma y función específicas.
Contenido
- ¿Cómo se descubrió el código genético?
- ¿Cómo se transfiere la información genética?
- Características del código genético
- Usos incorrectos del término "código genético"
- Tabla del código genético estándar
- Aminoácidos especiales
- Pequeñas variaciones del código genético
- Origen del código genético
- Galería de imágenes
- Véase también
¿Cómo se descubrió el código genético?

Después de que Francis Crick, Rosalind Franklin, James Watson y Maurice Wilkins nos mostraran cómo es la estructura del ADN en 1953, los científicos empezaron a investigar cómo se traduce esa información para crear proteínas.
En 1955, Severo Ochoa y Marianne Grunberg-Manago descubrieron una enzima (una proteína que acelera reacciones) que podía fabricar ARN. Esto fue muy útil para crear ARN con secuencias específicas en el laboratorio. Por ejemplo, si solo ponían una "letra" (como el uracilo, U), podían crear una cadena de ARN solo con UUUUUU...
George Gamow propuso que el código genético usaba grupos de tres letras (tripletes) para formar los aminoácidos. La primera prueba de que los codones eran de tres letras la dieron Crick y sus colegas.
En 1961, Marshall Warren Nirenberg y Heinrich J. Matthaei hicieron un experimento clave. Usaron un ARN hecho solo de uracilos (UUU...) y descubrieron que solo producía un aminoácido: la fenilalanina. Así supieron que el codón UUU significaba fenilalanina. Luego, Nirenberg y Philip Leder lograron descifrar 54 codones más.
Más tarde, Har Gobind Khorana completó el resto del código. Y Robert W. Holley descubrió la estructura del ARN de transferencia (ARNt), una molécula que ayuda a llevar los aminoácidos correctos al lugar donde se están construyendo las proteínas. Por todo este trabajo, Khorana, Holley y Nirenberg recibieron el Premio Nobel en 1968.
¿Cómo se transfiere la información genética?
La información genética de un organismo está en su genoma, que se encuentra en el ADN (o en el ARN para algunos virus). Una parte del genoma que contiene las instrucciones para hacer una proteína o un ARN se llama gen.
Los genes que fabrican proteínas están hechos de unidades de tres nucleótidos, los codones, y cada uno de ellos indica un aminoácido.
Cada nucleótido tiene tres partes: un fosfato, un azúcar (desoxirribosa en el ADN y ribosa en el ARN) y una de las cuatro bases nitrogenadas (A, T, C, G en ADN; A, U, C, G en ARN). En el ADN, la A siempre se une con la T, y la C con la G. En el ARN, la T se reemplaza por la U.
Para construir una proteína, la información de un gen en el ADN se copia primero a una molécula de ARN mensajero (ARNm). Este ARNm viaja a una parte de la célula llamada ribosoma. Allí, el ARNm se "lee" y se traduce en una cadena de aminoácidos.
En este proceso, los ARN de transferencia (ARNt) son muy importantes. Cada ARNt lleva un aminoácido específico y tiene una parte que "encaja" con un codón del ARNm. Así, los ARNt se aseguran de que los aminoácidos se coloquen en el orden correcto para formar la proteína.
Como cada codón tiene tres nucleótidos, hay 64 combinaciones posibles. Por ejemplo, si tenemos una secuencia de ARN como UUUAAACCC, y la lectura empieza en la primera U, tendríamos tres codones: UUU, AAA y CCC. Cada uno de ellos indicaría un aminoácido, y así se formaría una proteína con tres aminoácidos específicos.
Características del código genético
Universalidad: ¿Es el mismo para todos?
El código genético es casi el mismo para todos los seres vivos que conocemos, incluyendo virus y partes de las células. Por ejemplo, el codón UUU siempre significa el aminoácido fenilalanina, ya sea en bacterias, arqueas o en nosotros. Esto sugiere que el código genético apareció una sola vez en la historia de la vida en la Tierra.
Aunque es muy universal, existen algunas pequeñas diferencias. Se han encontrado 22 versiones del código genético, que varían un poco del "código genético estándar". La mayoría de estas diferencias se encuentran en las mitocondrias, que son como las "centrales de energía" de nuestras células y tienen su propio ADN.
Especificidad y continuidad: ¿Cómo se lee?
Cada codón solo codifica un aminoácido. Esto es muy importante para que las proteínas se construyan de forma precisa. Además, los codones se leen uno tras otro, sin saltos ni espacios, como si fueran palabras en una frase sin comas. La lectura siempre va en una dirección específica, desde el codón de inicio hasta el codón de parada.
Degeneración: ¿Hay repeticiones?
El código genético tiene "redundancia", lo que significa que varios codones pueden codificar el mismo aminoácido. Por ejemplo, tanto GAA como GAG codifican el aminoácido ácido glutámico. Pero, un codón nunca codifica dos aminoácidos diferentes.
A menudo, las diferencias entre los codones que codifican el mismo aminoácido están en la tercera "letra". Esto hace que si hay un pequeño error o cambio (una mutación) en esa tercera letra, es más probable que no afecte al aminoácido final, lo que ayuda a proteger la proteína de cambios dañinos.
¿Cómo se agrupan los codones?
Una ventaja de esta redundancia es que muchos errores en el código genético no causan problemas graves. A veces, una mutación no cambia el aminoácido o lo cambia por uno muy parecido, manteniendo la función de la proteína. Por ejemplo, los codones que empiezan con "NUN" (donde N es cualquier letra) suelen codificar aminoácidos que no se mezclan bien con el agua.
Aun así, algunas mutaciones pueden causar problemas. Un ejemplo famoso es la anemia de células falciformes, donde un solo cambio en un codón hace que un aminoácido (glutamato) se cambie por otro (valina). Esto altera la hemoglobina (la proteína que lleva oxígeno en la sangre) y hace que los eritrocitos (glóbulos rojos) se deformen.
Usos incorrectos del término "código genético"
A veces, en las noticias o en el lenguaje común, se usa la expresión "código genético" de forma incorrecta, como si fuera lo mismo que genoma, genotipo o ADN.
Por ejemplo, frases como "se analizó el código genético de los restos y coincidió con el de la persona desaparecida" o "se creará una base de datos con el código genético de todos los ciudadanos" son científicamente incorrectas. No se puede hablar del "código genético de una persona específica", porque el código genético es el mismo para casi todos los seres vivos. Lo que es único de cada persona es su genotipo, que es el conjunto de sus genes específicos.
Tabla del código genético estándar
La siguiente tabla muestra cómo se traduce cada codón en un aminoácido. El ARN se lee de izquierda a derecha (5' a 3').
| apolar | polar | básico | ácido | codón de parada |
| 2.ª base | |||||
|---|---|---|---|---|---|
| U | C | A | G | ||
| 1.ª base |
U | UUU (Phe/F) Fenilalanina UUC (Phe/F) Fenilalanina |
UCU (Ser/S) Serina UCC (Ser/S) Serina |
UAU (Tyr/Y) Tirosina UAC (Tyr/Y) Tirosina |
UGU (Cys/C) Cisteína UGC (Cys/C) Cisteína |
| UUA (Leu/L) Leucina | UCA (Ser/S) Serina | UAA Parada (Ocre) | UGA Parada (Ópalo) | ||
| UUG (Leu/L) Leucina | UCG (Ser/S) Serina | UAG Parada (Ámbar) | UGG (Trp/W) Triptófano | ||
| C | CUU (Leu/L) Leucina CUC (Leu/L) Leucina |
CCU (Pro/P) Prolina CCC (Pro/P) Prolina |
CAU (His/H) Histidina CAC (His/H) Histidina |
CGU (Arg/R) Arginina CGC (Arg/R) Arginina |
|
| CUA (Leu/L) Leucina CUG (Leu/L) Leucina |
CCA (Pro/P) Prolina CCG (Pro/P) Prolina |
CAA (Gln/Q) Glutamina
CAG (Gln/Q) Glutamina |
CGA (Arg/R) Arginina CGG (Arg/R) Arginina |
||
| A | AUU (Ile/I) Isoleucina AUC (Ile/I) Isoleucina |
ACU (Thr/T) Treonina ACC (Thr/T) Treonina |
AAU (Asn/N) Asparagina AAC (Asn/N) Asparagina |
AGU (Ser/S) Serina AGC (Ser/S) Serina |
|
| AUA (Ile/I) Isoleucina | ACA (Thr/T) Treonina | AAA (Lys/K) Lisina | AGA (Arg/R) Arginina | ||
| AUG (Met/M) Metionina, Comienzo | ACG (Thr/T) Treonina | AAG (Lys/K) Lisina | AGG (Arg/R) Arginina | ||
| G | GUU (Val/V) Valina GUC (Val/V) Valina |
GCU (Ala/A) Alanina GCC (Ala/A) Alanina |
GAU (Asp/D) Ácido aspártico GAC (Asp/D) Ácido aspártico |
GGU (Gly/G) Glicina GGC (Gly/G) Glicina |
|
| GUA (Val/V) Valina GUG (Val/V) Valina |
GCA (Ala/A) Alanina GCG (Ala/A) Alanina |
GAA (Glu/E) Ácido glutámico GAG (Glu/E) Ácido glutámico |
GGA (Gly/G) Glicina GGG (Gly/G) Glicina |
||
El codón AUG es especial porque codifica la metionina y también es la señal de inicio para que la célula empiece a construir una proteína.
La siguiente tabla muestra qué codones codifican cada aminoácido.
| Ala (A) | GCU, GCC, GCA, GCG | Lys (K) | AAA, AAG |
|---|---|---|---|
| Arg (R) | CGU, CGC, CGA, CGG, AGA, AGG | Met (M) | AUG |
| Asn (N) | AAU, AAC | Phe (F) | UUU, UUC |
| Asp (D) | GAU, GAC | Pro (P) | CCU, CCC, CCA, CCG |
| Cys (C) | UGU, UGC | Sec (U) | UGA |
| Gln (Q) | CAA, CAG | Ser (S) | UCU, UCC, UCA, UCG, AGU, AGC |
| Glu (E) | GAA, GAG | Thr (T) | ACU, ACC, ACA, ACG |
| Gly (G) | GGU, GGC, GGA, GGG | Trp (W) | UGG |
| His (H) | CAU, CAC | Tyr (Y) | UAU, UAC |
| Ile (I) | AUU, AUC, AUA | Val (V) | GUU, GUC, GUA, GUG |
| Leu (L) | UUA, UUG, CUU, CUC, CUA, CUG | ||
| Comienzo | AUG | Parada | UAG, UGA, UAA |
Aminoácidos especiales
Además de los 20 aminoácidos comunes, existen otros dos que son codificados en algunas situaciones y en ciertos organismos: la selenocisteína y la pirrolisina.
- La selenocisteína (Sec, U) se encuentra en muchas enzimas importantes. Está codificada por el codón UGA (que normalmente es una señal de parada) cuando hay una secuencia especial cerca.
- La pirrolisina (Pyl, O) se encuentra en algunas enzimas de arqueas metanógenas. Está codificada por el codón UAG (que también suele ser de parada) cuando hay otra secuencia especial presente.
Pequeñas variaciones del código genético
Aunque el código genético es muy parecido en todas las formas de vida, hay algunas pequeñas diferencias. Se han identificado 22 códigos genéticos distintos. La mayoría de estas variaciones se encuentran en las mitocondrias de diferentes organismos. Por ejemplo, en las mitocondrias de los vertebrados, algunos codones que normalmente significan "parada" o un aminoácido específico, pueden codificar otro aminoácido.
Origen del código genético
El hecho de que el código genético sea tan similar en todos los seres vivos sugiere que se estableció muy al principio de la historia de la vida en la Tierra y que todas las formas de vida actuales comparten un origen común.
Los científicos creen que el código genético no es una asignación al azar de codones a aminoácidos. Por ejemplo, los aminoácidos que se forman de manera similar suelen tener codones con la misma primera letra. Además, los aminoácidos con propiedades parecidas (como si les gusta o no el agua) también tienden a tener codones similares.
Algunos experimentos sugieren que, al principio, las proteínas podrían haberse formado directamente sobre el ARN, sin la ayuda de todas las moléculas complejas que vemos hoy. Se piensa que el código genético actual pudo haber evolucionado a partir de uno más simple, añadiendo nuevos aminoácidos con el tiempo.
También se cree que la selección natural (el proceso por el cual los organismos mejor adaptados sobreviven y se reproducen) ha favorecido un código que minimiza los efectos de los errores. Esto significa que si hay una pequeña mutación, es menos probable que cause un daño grave a la proteína.
Galería de imágenes
-
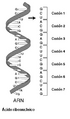
Serie de codones en un segmento de ARN. Cada codón se compone de tres nucleótidos que codifican un aminoácido específico.

Véase también
 En inglés: Genetic code Facts for Kids
En inglés: Genetic code Facts for Kids
