
Prueba de Turing para niños
La prueba de Turing es una forma de evaluar si una máquina puede mostrar un comportamiento tan inteligente que sea difícil distinguirlo del de un ser humano. Fue propuesta por el famoso matemático Alan Turing en 1950.
Imagina que una persona, a la que llamaremos el "evaluador", conversa por escrito con dos participantes: uno es un ser humano y el otro es una máquina. El evaluador no puede ver a ninguno de los dos, solo lee sus respuestas. Si el evaluador no puede saber con seguridad cuál es la máquina y cuál es el humano después de un tiempo, entonces la máquina habría "pasado" la prueba.
Turing sugirió que si la máquina lograba engañar al evaluador el 70% de las veces después de 5 minutos de conversación, se consideraría que había pasado la prueba. Esta prueba no busca saber si la máquina responde correctamente a las preguntas, sino si sus respuestas son tan parecidas a las de un humano que el evaluador no puede diferenciarlas.
Alan Turing presentó esta idea en su ensayo Computing Machinery and Intelligence en 1950, mientras trabajaba en la Universidad de Mánchester. Su pregunta inicial era: "¿Pueden pensar las máquinas?". Como la palabra "pensar" es difícil de definir, la cambió por una pregunta más clara: "¿Podrán las computadoras digitales imaginables jugar bien al juego de imitación?". Turing creía que esta nueva pregunta sí se podía responder.
Desde su creación, la prueba de Turing ha sido muy importante y ha generado muchos debates en el campo de la filosofía de la inteligencia artificial.
Contenido
- ¿Cómo surgió la idea de la prueba de Turing?
- Diferentes formas de entender la prueba de Turing
- Puntos fuertes de la prueba de Turing
- Limitaciones de la prueba de Turing
- Variantes de la prueba de Turing
- Predicciones sobre la prueba de Turing
- Eventos y conferencias sobre la prueba de Turing
- Galería de imágenes
- Véase también
¿Cómo surgió la idea de la prueba de Turing?
Orígenes filosóficos de la inteligencia artificial
La pregunta de si las máquinas pueden pensar no es nueva. Ha sido un tema de debate entre diferentes formas de entender la mente. Por ejemplo, René Descartes, un filósofo del siglo XVII, ya pensaba en máquinas que podían reaccionar a las personas. Sin embargo, él creía que estas máquinas no podrían responder de forma adecuada a todo lo que se les dijera, como sí lo haría un humano. Esto abrió la puerta a la idea de que la capacidad de conversar de forma inteligente podría ser una clave para distinguir a los humanos de las máquinas.
Otro pensador, Denis Diderot, en sus Pensamientos filosóficos, mencionó una idea similar a la prueba de Turing: "Si se encuentra un loro que puede responder a todo, se le consideraría un ser inteligente sin duda alguna". Esto muestra que la idea de evaluar la inteligencia a través de la conversación ya existía.
En 1936, el filósofo Alfred Ayer también propuso una forma de saber si otras personas tienen conciencia como nosotros. Su idea era que si algo no pasaba una "prueba de conciencia", entonces no estaba consciente. Aunque no es exactamente la prueba de Turing, es similar en el sentido de usar una prueba para evaluar una cualidad mental.
Alan Turing y su visión de las máquinas
Alan Turing, un brillante matemático británico, ya estaba pensando en la inteligencia de las máquinas mucho antes de que se estableciera el campo de la IA en 1956. Desde 1941, Turing exploraba si una máquina podía mostrar un comportamiento inteligente.
En 1947, en un informe llamado "Maquinaria inteligente", Turing propuso un juego que se parece mucho a su futura prueba. Imaginó un juego de ajedrez donde tres personas (A, B y C) participan. A y C son jugadores no muy buenos, y B es quien opera la máquina. C juega contra A o la máquina, y el objetivo es que C tenga dificultades para saber contra quién está jugando.
Su texto más famoso sobre este tema fue "Computing Machinery and Intelligence". En él, Turing propuso cambiar la pregunta de "¿Pueden pensar las máquinas?" a "¿Pueden las máquinas hacer lo que nosotros (como seres pensantes) hacemos?". La ventaja de esta nueva pregunta es que se enfoca en las capacidades que podemos observar.
Para demostrar su idea, Turing se inspiró en un "Juego de imitación" de fiesta. En este juego, un hombre y una mujer están en cuartos separados, y otros jugadores intentan adivinar quién es quién haciendo preguntas y leyendo las respuestas escritas. El objetivo de los participantes en los cuartos es convencer a los demás de que son el otro.
Turing adaptó este juego para su prueba:
Nos hacemos la pregunta, “¿Qué pasaría si una máquina toma el papel de A en este juego?” ¿Se equivocaría tan frecuentemente el interrogador en esta nueva versión del juego que cuando era jugado por un hombre y una mujer? Estas preguntas sustituyen la pregunta original “¿Pueden pensar las máquinas?”.
Más tarde, Turing propuso una versión donde un juez conversa con una computadora y un hombre. En una transmisión de la BBC, sugirió que un jurado hiciera preguntas a una computadora, y el objetivo de la máquina sería engañar a la mayoría del jurado para que creyeran que era un humano.
Programas que intentaron pasar la prueba: ELIZA y PARRY
En 1966, Joseph Weizenbaum creó un programa llamado ELIZA. Este programa analizaba las palabras clave en lo que escribía el usuario y respondía de una manera que imitaba a un terapeuta. ELIZA logró engañar a algunas personas, haciéndoles creer que hablaban con una persona real. Por eso, ELIZA es considerado uno de los primeros programas en acercarse a pasar la prueba de Turing, aunque esto es un tema de debate.
En 1972, Kenneth Colby creó PARRY, un programa que intentaba simular el comportamiento de una persona con ciertas condiciones mentales. PARRY fue probado con una variación de la prueba de Turing. Un grupo de psiquiatras experimentados conversó con pacientes reales y con computadoras que ejecutaban PARRY. Los psiquiatras solo pudieron identificar correctamente a los humanos el 48% de las veces, lo que es similar a adivinar al azar.
En el siglo XXI, programas similares, llamados "bots conversacionales", han seguido engañando a la gente. Por ejemplo, "CyberLover", un programa malicioso, coqueteaba con usuarios en línea para obtener información personal.
El experimento de la "habitación china"
En 1980, el filósofo John Searle propuso el experimento de la "habitación china". Con este experimento, Searle argumentó que la prueba de Turing no es suficiente para saber si una máquina realmente "piensa". Él decía que un programa como ELIZA podía pasar la prueba manipulando símbolos sin entender realmente lo que significaban. Por lo tanto, Searle concluyó que la prueba de Turing no puede demostrar que una máquina piensa de la misma manera que un humano. Este argumento, al igual que la prueba de Turing, ha sido muy debatido.
El Premio Loebner: una competición anual

El Premio Loebner es una competición anual que se celebra desde 1991 para poner a prueba la capacidad de las máquinas en la prueba de Turing. Fue creado por Hugh Loebner para impulsar la investigación en IA.
En la primera competición en 1991, el programa ganador logró engañar a algunos evaluadores porque imitaba errores humanos al escribir. Esto mostró algunas de las limitaciones de la prueba de Turing, ya que los evaluadores menos experimentados eran engañados fácilmente.
Aunque los premios más grandes (de plata y oro) no se han ganado todavía, cada año se entrega una medalla de bronce al sistema que demuestra el comportamiento conversacional más "humano". Programas como A.L.I.C.E. y Jabberwacky han ganado este premio varias veces.
En 2014, el robot conversacional ruso Eugene Goostman ganó una competición especial de la prueba de Turing, logrando convencer al 33% de los jueces de que era humano. Este robot se presentaba como un niño ucraniano de 13 años que estaba aprendiendo inglés. Los organizadores de la competición creyeron que la prueba había sido "aprobada por primera vez" en este evento. Sin embargo, algunos expertos señalaron que el resultado no era tan impresionante, ya que solo un tercio de los jueces fue engañado y el personaje del robot era muy específico.
Diferentes formas de entender la prueba de Turing
Existen varias interpretaciones de la prueba de Turing. Algunos expertos, como Saul Traigner, dicen que hay al menos tres versiones principales.
El juego de la imitación original
La versión original que describió Turing era un juego de fiesta con tres jugadores. El jugador A es un hombre, el jugador B es una mujer, y el jugador C (el evaluador) puede ser de cualquier género. El evaluador no ve a los otros dos y se comunica con ellos por notas escritas. El objetivo del evaluador es adivinar quién es el hombre y quién es la mujer. El jugador A intenta engañar al evaluador, mientras que el jugador B intenta ayudarlo.
Turing propuso que una computadora tomara el papel del jugador A, pretendiendo ser una mujer. Si la computadora lograba engañar al evaluador tan a menudo como lo haría un hombre en el mismo papel, entonces se podría decir que la computadora es inteligente.
La interpretación estándar de la prueba de Turing

La forma más común de entender la prueba de Turing hoy en día es la "interpretación estándar". En esta versión, el jugador A es una computadora y el jugador B es un humano (sin importar su género). El objetivo del evaluador no es adivinar el género, sino saber cuál es la computadora y cuál es el humano. Si el evaluador no puede diferenciarlos, la máquina pasa la prueba.
Hay un debate sobre si el evaluador debe saber que uno de los participantes es una computadora. Turing no lo especificó claramente. Sin embargo, estudios han demostrado que si los evaluadores saben que hay una computadora, esto puede influir en sus decisiones.
Puntos fuertes de la prueba de Turing
Sencillez y utilidad
Una de las mayores ventajas de la prueba de Turing es su simplicidad. Es difícil definir exactamente qué es la "inteligencia" o el "pensamiento". La prueba de Turing, aunque no es perfecta, ofrece una forma práctica y medible de abordar esta pregunta filosófica.
Variedad de temas y habilidades
El formato de la prueba permite al evaluador hacer preguntas sobre una gran variedad de temas. Para pasar la prueba, una máquina debe ser capaz de usar el lenguaje natural, razonar, tener conocimientos y aprender. Si se le añaden elementos como video o la manipulación de objetos, la prueba puede evaluar también la visión computacional y la robótica. Esto significa que la prueba de Turing abarca muchos de los desafíos que la investigación en inteligencia artificial busca resolver.
Por ejemplo, la máquina Watson de IBM demostró su capacidad al ganar en el programa de televisión Jeopardy!, donde respondía preguntas de conocimiento general.
Énfasis en la inteligencia emocional y artística
A pesar de ser un matemático, Turing no propuso una prueba que solo evaluara conocimientos técnicos. En cambio, su prueba original se basaba en un juego de fiesta donde la computadora debía pretender ser una mujer. Esto implicaba que las preguntas no serían solo sobre hechos, sino que la máquina debería mostrar empatía y sensibilidad artística.
Por ejemplo, en uno de sus diálogos imaginarios, Turing incluye una conversación sobre poesía:
- Interrogador: En la primera línea de tu soneto se lee: “Podré compararla con un día de verano”, ¿acaso no funcionaría “un día de primavera” de igual o mejor manera?
- Testigo: No funcionaría.
- Interrogador: ¿Qué tal “un día de invierno”? Eso debería funcionar.
- Testigo: Si, pero nadie quiere ser comparado con un día de invierno.
Esto muestra que Turing consideraba la empatía y la sensibilidad estética como partes importantes de la inteligencia.
Limitaciones de la prueba de Turing
Turing no dijo que su prueba fuera la única forma de medir la inteligencia. Su objetivo era ofrecer una alternativa clara a la palabra "pensar" y sugerir cómo avanzar en la investigación. Sin embargo, la idea de usar la prueba de Turing como una medida de la "capacidad de pensar" de una máquina ha recibido críticas.
Comportamiento humano vs. inteligencia general
La prueba de Turing evalúa si una computadora se comporta como un ser humano, no directamente si es inteligente. Como el comportamiento humano y el comportamiento inteligente no son siempre lo mismo, la prueba puede tener dos problemas:
- Comportamientos humanos no inteligentes: La prueba de Turing requiere que la máquina imite todos los comportamientos humanos, incluso los que no son inteligentes, como cometer errores de escritura o mentir. Si una máquina no imita estos comportamientos, podría reprobar la prueba. Por ejemplo, el ganador del Premio Loebner en 1992 lo logró en parte por su habilidad para "imitar errores humanos al escribir".
- Comportamientos inteligentes inhumanos: La prueba de Turing no evalúa comportamientos muy inteligentes, como resolver problemas muy difíciles o tener ideas originales. De hecho, si una máquina fuera demasiado inteligente y resolviera un problema que un humano no podría, el evaluador sabría que no es humana y la máquina reprobaría la prueba. Por esta razón, la prueba no es útil para evaluar sistemas que son más inteligentes que los humanos.
Inteligencia real vs. inteligencia simulada
La prueba de Turing solo se enfoca en el comportamiento externo de la máquina. Esto significa que una máquina podría pasar la prueba simplemente simulando el comportamiento humano sin realmente "pensar" o tener una "mente". El experimento de la "habitación china" de John Searle busca demostrar esto: un programa podría manipular símbolos sin entenderlos, lo que no significa que esté pensando de verdad.
La ingenuidad de los evaluadores
En la práctica, los resultados de la prueba pueden depender mucho de la actitud o la ingenuidad del evaluador. Turing mencionó que el "evaluador promedio" no debería tener más del 70% de posibilidades de acertar.
Los bots conversacionales como ELIZA han engañado a personas varias veces, especialmente cuando los evaluadores no sabían que podían estar interactuando con una computadora. Para parecer humano, una máquina no necesita ser inteligente, solo necesita una similitud superficial con el comportamiento humano.
Michael Shermer señala que los humanos a menudo tienden a ver objetos no humanos como si fueran humanos, un error llamado "falacia antropomórfica". Esto puede hacer que la prueba de Turing sea menos exigente, a menos que los evaluadores estén entrenados para evitar esta tendencia.
Irrelevancia para la investigación de IA
Muchos investigadores de IA famosos argumentan que intentar pasar la prueba de Turing es una distracción de investigaciones más importantes. La prueba no es un objetivo principal en la investigación académica o comercial de la IA.
Hay formas más sencillas de probar un programa. Por ejemplo, para saber si un programa es bueno en la planificación automatizada o el reconocimiento de objetos, los investigadores simplemente le dan esas tareas directamente. Es como probar un avión por su capacidad de volar, no por si vuela como un pájaro.
Además, crear simulaciones de humanos es un problema muy difícil que no es necesario resolver para los objetivos básicos de la investigación de IA, que es crear máquinas inteligentes que resuelvan problemas.
Variantes de la prueba de Turing
A lo largo de los años, se han propuesto varias versiones de la prueba de Turing.
Prueba de Turing inversa y CAPTCHA

Una modificación interesante es la prueba de Turing inversa, donde el objetivo es que la máquina determine si está interactuando con un humano o con otra computadora.
CAPTCHA es un ejemplo de prueba de Turing inversa. Cuando ves una imagen con letras distorsionadas en un sitio web y te piden que las escribas, el objetivo es que solo un humano pueda leerlas y escribirlas correctamente, evitando que programas automáticos accedan al sitio.
Prueba de Turing total
La "Prueba de Turing Total" es una variación que añade más requisitos. El evaluador también juzga las capacidades de percepción de la máquina (requiriendo visión computacional) y su habilidad para manipular objetos (requiriendo robótica).
Prueba de la señal de inteligencia mínima
Esta prueba, propuesta por Chris McKinstry, es una versión muy simplificada de la prueba de Turing. Solo se permiten respuestas de "sí" o "no" para enfocarse únicamente en la capacidad de pensar. Esto elimina problemas como la necesidad de simular comportamientos humanos no inteligentes y permite evaluar sistemas que superan la inteligencia humana.
Predicciones sobre la prueba de Turing
Turing predijo que las máquinas pasarían la prueba tarde o temprano. Estimó que para el año 2000, las máquinas con suficiente memoria podrían engañar al 30% de los jueces humanos en una prueba de 5 minutos. También predijo que el aprendizaje de las máquinas sería esencial para construir máquinas poderosas, una idea que hoy es fundamental en la IA.
El futurista Ray Kurzweil ha predicho que las máquinas que pasen la prueba de Turing serán creadas en el futuro cercano. En 1990, estimó que esto ocurriría alrededor de 2020, y en 2005, cambió su estimación a 2029.
Existe una apuesta de $20,000 entre Mitch Kapor y Ray Kurzweil sobre si una máquina pasará la prueba de Turing para el año 2029.
Eventos y conferencias sobre la prueba de Turing
Coloquio de Turing de 1990
En 1990, para celebrar el 40 aniversario de la publicación del ensayo de Turing "Computing Machinery and Intelligence", se realizaron dos eventos importantes. Uno fue el Coloquio de Turing en la Universidad de Sussex, donde expertos de diferentes áreas discutieron el pasado, presente y futuro de la prueba. El otro fue la primera competición anual del Premio Loebner.
Simposios y convenciones recientes
A lo largo de los años, se han celebrado varias conferencias y simposios para discutir la prueba de Turing y sus implicaciones. Por ejemplo, en 2005, la Universidad de Surrey fue sede de una reunión de desarrolladores de entidades conversacionales artificiales.
En 2008 y 2010, se llevaron a cabo simposios dedicados a la prueba de Turing, donde se reunieron expertos para debatir sobre su validez y futuro.
El Año de Turing y Turing100 en 2012
El año 2012 fue el centenario del nacimiento de Alan Turing, y se celebraron muchos eventos en su honor. El grupo Turing100 organizó una prueba de Turing especial en Bletchley Park para conmemorar su legado.
Galería de imágenes
-
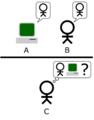
La "interpretación estándar" de la prueba de Turing, en la cual a la entidad C, el interrogador, le es dada la tarea de tratar de determinar qué entidad —¿A o B?— es una computadora y cual un ser humano. El interrogador se limita a la utilización de las respuestas a las preguntas escritas para tomar la determinación. Imagen adaptada de Saygin, 2000.
-
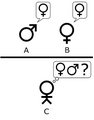
El juego de la imitación, como descrito por Alan Turing en “Computing Machinery and Intelligence”. El jugador C, por medio de preguntas escritas, intenta determinar cuál de los otros dos jugadores es mujer y cual hombre. El jugador A, el hombre, trata de engañar al jugador C para que yerre su decisión mientras que el jugador B trata de ayudarlo. Figura adaptada de Saygin, 2000.
-
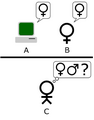
La prueba del Juego Original de la Imitación, en la cual el jugador A es reemplazado con una computadora. El ordenador tiene el papel de un hombre mientras el jugador B tiene el papel de auxiliar al interrogador. Figura adaptada de Saygin, 2000.
-
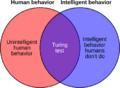
Una ilustración de una de las debilidades de la prueba de Turing.

Véase también
 En inglés: Turing test Facts for Kids
En inglés: Turing test Facts for Kids
