
Mínimos cuadrados para niños
Los Mínimos Cuadrados son una técnica matemática que nos ayuda a encontrar la línea o curva que mejor se ajusta a un conjunto de puntos de datos. Imagina que tienes varios puntos dispersos en un gráfico y quieres dibujar una línea que pase lo más cerca posible de todos ellos. Los Mínimos Cuadrados te dan una forma precisa de hacer esto.
El objetivo principal es minimizar la suma de los cuadrados de las "distancias" (llamadas residuos) entre cada punto de tus datos y la línea o curva que estás tratando de encontrar. Al hacer esto, se asegura que la línea o curva sea el "mejor ajuste" posible para esos datos.
Esta técnica es muy útil en muchas áreas, como la ciencia, la ingeniería y la economía, para analizar datos, predecir tendencias o entender relaciones entre diferentes cosas.
El algoritmo LMS (del inglés, Least-Mean-Square algorithm) es una versión de Mínimos Cuadrados que se usa en filtros especiales llamados filtros adaptativos. Ayuda a estos filtros a ajustarse y mejorar su rendimiento con el tiempo, minimizando el error entre lo que se espera y lo que realmente se obtiene.
Desde el punto de vista de las estadísticas, para que el método de Mínimos Cuadrados funcione bien, los errores en cada medición deben ser aleatorios. Un teorema importante, el teorema de Gauss-Márkov, dice que los resultados de Mínimos Cuadrados son muy buenos y no tienen un "sesgo" (no favorecen un lado).
Contenido
¿Para qué se usan los Mínimos Cuadrados?
Los Mínimos Cuadrados se usan mucho para:
- Ajustar curvas: Encontrar la ecuación de una línea o curva que represente mejor un conjunto de datos.
- Optimización: Resolver problemas donde se busca el mejor resultado posible, como minimizar la energía o maximizar la información en un sistema.
- Predicciones: Si tienes datos históricos, puedes usar Mínimos Cuadrados para predecir lo que podría pasar en el futuro. Por ejemplo, cómo crecerá una población o cómo cambiará el clima.
Historia de los Mínimos Cuadrados

La historia de los Mínimos Cuadrados es muy interesante y está ligada al descubrimiento de un pequeño planeta.
El 1 de enero de 1801, un astrónomo italiano llamado Giuseppe Piazzi descubrió un nuevo objeto en el espacio, al que llamó Ceres. Pudo observarlo durante 40 días. Después de eso, Ceres se perdió de vista porque su órbita era difícil de calcular con las herramientas de la época.
Muchos científicos intentaron predecir dónde estaría Ceres para poder encontrarlo de nuevo. La mayoría de los cálculos no fueron lo suficientemente precisos. Sin embargo, un joven matemático alemán de 24 años, Carl Friedrich Gauss, logró calcular su trayectoria con una precisión asombrosa. Gracias a sus cálculos, otro astrónomo, Franz Xaver von Zach, pudo reencontrar a Ceres a finales de ese año.
Gauss había desarrollado los principios de su método, que era el de Mínimos Cuadrados, cuando tenía solo 18 años, en 1795. Sin embargo, no publicó su trabajo hasta 1809, en un libro sobre mecánica de los cuerpos celestes.
Curiosamente, otro matemático, el francés Adrien-Marie Legendre, desarrolló el mismo método de forma independiente en 1805 y lo publicó antes que Gauss. Por eso, a veces se discute quién fue el primero en descubrirlo.
En 1829, Gauss demostró por qué su método era tan bueno. Explicó que los Mínimos Cuadrados son la mejor manera de hacer estas aproximaciones en muchos casos, algo que hoy conocemos como el teorema de Gauss-Márkov.
¿Cómo funciona el método de Mínimos Cuadrados?
Imagina que tienes varios puntos en un gráfico, cada uno con una posición (x, y). Quieres encontrar una función (como una línea recta o una curva) que se acerque lo más posible a todos esos puntos.
1. Definir la función: Primero, eliges qué tipo de función quieres usar. Por ejemplo, si crees que tus puntos se parecen a una línea recta, usarías la ecuación de una recta (y = ax + b). Si crees que se parecen a una curva, podrías usar una función cuadrática (y = ax² + bx + c). 2. Calcular el error: Para cada punto de tus datos, calculas la diferencia entre el valor 'y' real del punto y el valor 'y' que la función que elegiste predice para ese mismo 'x'. A esta diferencia se le llama error o residuo. 3. Minimizar el error cuadrático: En lugar de sumar los errores directamente (porque algunos serían positivos y otros negativos y se anularían), lo que se hace es elevar cada error al cuadrado y luego sumarlos todos. Esto asegura que todos los errores sean positivos y que los errores grandes tengan un mayor impacto. El método de Mínimos Cuadrados busca los valores de los coeficientes de tu función (como 'a' y 'b' en una recta) que hagan que esta suma de errores al cuadrado sea lo más pequeña posible. De ahí viene el nombre "Mínimos Cuadrados".
El ejemplo de la línea recta
Uno de los usos más comunes de los Mínimos Cuadrados es encontrar la línea recta que mejor se ajusta a un conjunto de puntos. Esto se conoce como regresión lineal.
Si tienes muchos puntos (x, y) y quieres encontrar la recta `y = ax + b` que mejor los represente, el método de Mínimos Cuadrados te ayuda a calcular los valores de 'a' (la pendiente de la recta) y 'b' (el punto donde la recta cruza el eje Y) que minimizan la suma de los cuadrados de las distancias de los puntos a la recta.
Esto es muy útil para ver tendencias. Por ejemplo, si graficas la altura de una planta a lo largo de varias semanas, puedes usar Mínimos Cuadrados para encontrar la línea recta que muestra cómo crece la planta en promedio.
Galería de imágenes
-
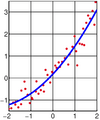
El resultado del ajuste de un conjunto de datos a una función cuadrática.

Ver también
- Regresión isotónica
- Filtro de mínimos cuadrados promedio
- Estimación de mínimos cuadrados de coeficientes para regresión lineal
- Regresión lineal
- Mínimos cuadrados móviles
- Mínimos cuadrados no lineales
- Análisis de regresión
- Regresión robusta
- Valor eficaz
- Teorema de Gauss-Márkov
- Mínimos cuadrados totales
- Mínimos cuadrados ordinarios
- Mínimos cuadrados ponderados
- Análisis de la varianza
- Ecuaciones normales del problema de cuadrados mínimos
- Algoritmo de Levenberg-Marquardt
Véase también
 En inglés: Least squares Facts for Kids
En inglés: Least squares Facts for Kids
