
Watson (inteligencia artificial) para niños
Watson es un sistema de inteligencia artificial muy avanzado, creado por la empresa IBM de Estados Unidos. Su nombre es un homenaje a Thomas J. Watson, quien fue el fundador y primer presidente de IBM.
Watson es especial porque puede entender y responder preguntas que le hacemos en lenguaje natural, es decir, como hablamos normalmente. Para hacer esto, usa una gran cantidad de información guardada en su base de datos interna. Esta información viene de muchos lugares, como enciclopedias, diccionarios, noticias y libros. También usa bases de datos especiales como DBpedia y WordNet.

Contenido
- ¿Cómo Watson ganó en Jeopardy!?
- ¿Cómo funciona Watson?
- ¿Cómo jugó Watson en el programa?
- Historia de Watson
- ¿Para qué se usará Watson en el futuro?
- Galería de imágenes
- Véase también
¿Cómo Watson ganó en Jeopardy!?
En febrero de 2011, Watson participó en un programa de televisión muy famoso en Estados Unidos llamado Jeopardy!. Durante tres días, compitió contra dos de los mejores concursantes humanos de la historia del programa: Brad Rutter y Ken Jennings.
Watson logró ganar el primer premio de $1.000.000. Ken Jennings y Brad Rutter recibieron $300.000 y $200.000, respectivamente. Los concursantes humanos donaron la mitad de sus ganancias a organizaciones de ayuda, y IBM también dividió las ganancias de Watson entre dos organizaciones benéficas.
¿Cómo fue el desempeño de Watson?
Watson fue muy rápido usando el dispositivo para responder en el juego. Sin embargo, tuvo algunas dificultades con categorías que tenían pistas muy cortas o con pocas palabras. Para cada pista, Watson mostraba en la pantalla sus respuestas más probables.
Durante el juego, Watson tenía acceso a 200 millones de páginas de contenido, que ocupaban cuatro terabytes de espacio. Esto incluía todo el texto de la Wikipedia en inglés. Es importante saber que Watson no estaba conectado a Internet durante la competencia.
¿Cómo funciona Watson?
Watson es un sistema diseñado para encontrar respuestas a preguntas. IBM lo describe como una aplicación que usa tecnologías avanzadas para entender el lenguaje, buscar información, organizar el conocimiento, razonar y aprender. Todo esto se basa en una tecnología de IBM llamada DeepQA.
La tecnología detrás de Watson
Watson está optimizado para tareas complejas. Esto es posible gracias a que usa muchos procesadores POWER7 trabajando al mismo tiempo y el software DeepQA.
Para el concurso de Jeopardy!, Watson usó 90 servidores IBM POWER 750. Cada servidor tenía un procesador de 3.5 GHz con 8 núcleos. En total, el sistema tenía 2880 núcleos de procesamiento POWER7 y 16 Terabytes de RAM. Esto le permitía procesar muchísima información de forma paralela.
Se estima que Watson puede procesar 500 gigabytes por segundo, lo que equivale a un millón de libros. El costo del hardware de Watson fue de aproximadamente $3.000.000. La información se guardaba en la memoria RAM de Watson para que pudiera acceder a ella muy rápido, ya que los discos duros son más lentos.
El software de Watson fue escrito usando los lenguajes de programación Java y C++. También usa herramientas como Hadoop para trabajar con muchos datos y UIMA para analizar textos. Además, utiliza el sistema operativo SUSE Linux Enterprise Server 11. IBM explica que Watson usa más de 100 técnicas diferentes para analizar el lenguaje, encontrar fuentes, generar ideas, buscar pruebas y clasificar las respuestas.
¿Cómo entiende y responde preguntas?
El sistema DeepQA
Para competir en Jeopardy!, el equipo de IBM necesitaba que Watson respondiera correctamente a más del 85% de las preguntas y fuera más rápido que los humanos en el 70% de ellas. Las preguntas de Jeopardy! son muy complejas, con lenguaje natural rico y a menudo ambiguo, y cubren muchos temas. Por eso, IBM desarrolló su propio sistema, DeepQA.
Recopilación de información
Antes de responder, Watson necesita tener mucha información. Primero, se le dan ejemplos de preguntas para que sepa qué tipo de información buscar. Luego, se le proporcionan fuentes iniciales como artículos y enciclopedias. A partir de ahí, el sistema busca más recursos en la web, los evalúa y los añade a su base de datos. Watson usa sistemas como PRISMATIC para organizar esta información.
Watson tiene datos de muchos tipos, incluyendo Wikipedia, Freebase, WordNet, DBPedia y la ontología Yago.
Análisis de la pregunta
Cuando Watson recibe una pregunta, lo primero que hace es entender qué se le está preguntando. Para esto, usa muchos algoritmos y sistemas expertos.
Clasificación de la pregunta
Watson clasifica la pregunta para saber qué tipo de respuesta necesita (una definición, un número, etc.). Esto le ayuda a elegir los mejores métodos para encontrar la respuesta.
Identificación de la clave y el tipo de respuesta
El focus de una pregunta es la parte que se refiere a la respuesta. Por ejemplo, en "Número de poemas a los cuales Emily Dickinson dio permiso para publicar", "Número de poemas" es el focus. El LAT (lexical answer type) es una palabra que indica el tipo de respuesta esperada, como "número" o "persona". Esto ayuda a Watson a saber si una respuesta es válida.
Detección de relaciones
Algunas preguntas contienen relaciones que Watson puede buscar directamente en bases de datos. Por ejemplo, si se pregunta por los estados que limitan con Florida, Watson podría buscar esa información en una tabla.
Descomposición de preguntas
Watson puede dividir una pregunta compleja en varias preguntas más pequeñas. Al responder cada sub-pregunta, aumenta la probabilidad de encontrar la respuesta correcta a la pregunta original. Algunas sub-preguntas se pueden responder al mismo tiempo, y otras necesitan una respuesta anterior para poder ser resueltas.
Búsqueda de posibles respuestas
En esta fase, Watson usa los resultados del análisis de la pregunta para buscar y generar posibles respuestas, llamadas "hipótesis".
Búsqueda inicial
Primero, Watson realiza una búsqueda general para encontrar cualquier contenido que pueda estar relacionado con la respuesta.
Generación de candidatos
Con los resultados de la búsqueda, Watson extrae "candidatos", que son posibles respuestas. Si la respuesta correcta no está entre estos candidatos, Watson no podrá encontrarla.
Filtrado de candidatos
Como se generan muchos candidatos, Watson realiza un "filtrado suave" para eliminar rápidamente las hipótesis menos probables. Esto ahorra tiempo y recursos. Por ejemplo, si la pregunta pide el nombre de una persona, Watson descartará todo lo que no sea un nombre.
Evaluación de las hipótesis
Los candidatos que pasan el filtro son analizados más a fondo. Watson busca pruebas que demuestren la validez de cada candidato y les asigna una puntuación.
Recopilación de pruebas
Watson busca textos donde el candidato aparezca en el contexto de la pregunta para encontrar pruebas.
Puntuación
Aquí se calcula qué tan seguro está Watson de que las pruebas apoyan a cada candidato. Se usan muchas técnicas para medir diferentes aspectos de la pregunta y la prueba.
Combinación de respuestas
Antes de elegir la respuesta final, Watson combina las respuestas que son equivalentes o muy similares. También fusiona sus puntuaciones y pruebas. Por ejemplo, si la pregunta pide el nombre de una persona, Watson agrupará todos los nombres que se refieran a la misma persona.
Clasificación y confianza
Finalmente, Watson estima qué tan correcta es cada hipótesis y las organiza en un "ranking". Para esto, usa aprendizaje automático, que se entrena con preguntas y respuestas conocidas. Con este ranking y nivel de confianza, Watson decide si debe responder la pregunta y cuál es la mejor respuesta.
¿Cómo jugó Watson en el programa?
Para cumplir con las reglas de Jeopardy!, Watson esperaba a que el presentador, Alex Trebek, terminara de leer cada pista. En ese momento, una luz se encendía, indicando que el sistema estaba listo para responder. El primer concursante que presionaba el botón de su zumbador ganaba la oportunidad de responder.
Watson recibía las pistas en formato de texto electrónico al mismo tiempo que los concursantes humanos. Luego, analizaba las pistas buscando palabras clave y frases para encontrar relaciones estadísticas. La gran innovación de Watson fue su capacidad para ejecutar rápidamente miles de algoritmos de análisis de lenguaje al mismo tiempo para encontrar la respuesta correcta. La probabilidad de que Watson acertara se medía por la cantidad de algoritmos que llegaban a la misma respuesta de forma independiente.
Watson era más rápido que los concursantes humanos al presionar el zumbador, excepto cuando los humanos se anticipaban a la señal. Después de presionar el botón, Watson hablaba con una voz electrónica, dando las respuestas en el formato de "respuesta y pregunta" que se usa en Jeopardy!.
Historia de Watson
La idea de Watson surgió después de que la computadora Deep Blue de IBM le ganara al campeón de ajedrez Garri Kaspárov en 1997. IBM buscaba un nuevo desafío. En 2004, Charles Lickel, un gerente de investigación de IBM, vio a Ken Jennings ganar en Jeopardy! y pensó que sería un gran reto para una computadora.
Al principio, fue difícil encontrar investigadores que quisieran asumir el desafío, ya que parecía mucho más complejo que el ajedrez. Finalmente, David Ferrucci aceptó. Antes de Watson, existía un sistema llamado "Piquant" que solo respondía correctamente al 35% de las pistas y tardaba varios minutos. Para Jeopardy!, Watson necesitaba responder en pocos segundos.
En las primeras pruebas en 2006, Watson solo respondía correctamente al 15% de las pistas. Los mejores concursantes humanos respondían al 95%. En 2007, el equipo de 15 personas se dio de tres a cinco años para resolver los problemas. Para 2008, Watson ya podía competir con campeones de Jeopardy!, y en febrero de 2010, les ganaba regularmente.
Watson fue un proyecto principalmente de IBM, pero también colaboraron profesores y estudiantes de varias universidades, como la Universidad Carnegie Mellon y el Instituto Tecnológico de Massachusetts.
En 2008, IBM contactó a Harry Friedman, el productor ejecutivo de Jeopardy!, para organizar la competencia. Hubo algunas preocupaciones. IBM temía que los guionistas del programa escribieran pistas que aprovecharan las debilidades de Watson. Para evitar esto, un tercero eligió las pistas al azar de programas no emitidos. El personal de Jeopardy! también pidió que Watson presionara el botón físicamente, como los humanos, aunque Watson seguía siendo más rápido con su "dedo robótico".
Para prepararse, IBM construyó una simulación del plató de Jeopardy! y realizó unos 100 simulacros. Watson ganó el 65% de esos partidos. Los partidos oficiales se grabaron en enero de 2011 y se transmitieron al mes siguiente.
¿Para qué se usará Watson en el futuro?
Según IBM, el objetivo de Watson es que las computadoras puedan interactuar de forma natural con las personas en muchas áreas, entendiendo sus preguntas y dando respuestas claras y justificadas.
IBM y Nuance Communications Inc. están trabajando juntos para desarrollar un producto comercial que use las capacidades de Watson para ayudar a los médicos a diagnosticar y tratar a los pacientes. Médicos de la Universidad de Columbia y la Universidad de Maryland están ayudando a identificar cómo Watson puede ser más útil en la medicina. También se ha sugerido que Watson podría usarse para investigaciones legales.
Watson se basa en servidores "IBM Power 750". IBM también planea vender el software DeepQA a grandes empresas. Aunque el costo inicial es alto, se espera que baje mucho en el futuro a medida que la tecnología mejore.
Galería de imágenes
-
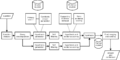
La arquitectura de alto nivel empleada por la tecnología DeepQA, que IBM utilizó específicamente para Watson.
-

Demostración de Watson desde una cabina de IBM en una demostración comercial.


Véase también
 En inglés: IBM Watson Facts for Kids
En inglés: IBM Watson Facts for Kids
- Deep Blue (computadora)
- Inteligencia artificial
- Procesamiento de lenguajes naturales
