
Retropropagación para niños
La retropropagación o propagación hacia atrás de errores es un método importante en el aprendizaje automático. Se usa para enseñar a las redes neuronales artificiales, que son como cerebros de computadora, a aprender de sus errores. Imagina que una red neuronal es un estudiante. La retropropagación es el proceso que le permite al estudiante saber qué tan bien lo hizo y cómo ajustar sus conocimientos para mejorar la próxima vez.
Este método funciona en dos pasos principales:
- Paso 1: Propagación hacia adelante: La información (como una imagen o un número) entra a la red. Pasa por varias capas de "neuronas" artificiales, como si fueran estaciones de procesamiento. Al final, la red da una respuesta.
- Paso 2: Propagación hacia atrás: La respuesta de la red se compara con la respuesta correcta que debería haber dado. Si hay un error, esa información de error se envía "hacia atrás" a través de la red. Cada neurona recibe una parte del error, dependiendo de cuánto contribuyó a él. Esto les ayuda a ajustar sus conexiones para que la próxima vez la respuesta sea más precisa.
Gracias a este proceso, las neuronas en las capas intermedias de la red aprenden a reconocer diferentes características o patrones en la información que reciben. Así, cuando la red ve algo nuevo, incluso si está un poco incompleto o tiene "ruido", puede reconocer patrones similares a los que aprendió.
Contenido
¿Qué es un Perceptrón?

Un perceptrón es un modelo matemático que imita cómo funciona una neurona en nuestro cerebro. Es la unidad básica de una red neuronal artificial.
Imagina que el perceptrón recibe varias "entradas" (como señales). Cada entrada tiene un "peso" que indica su importancia. El perceptrón suma todas estas entradas multiplicadas por sus pesos. Luego, el resultado pasa por una "función de activación", que decide si la neurona se "activa" (envía una señal) o no.
¿Cómo funciona un Perceptrón Multicapa?

Un Perceptrón multicapa es una red neuronal artificial que tiene varias capas de perceptrones, no solo una. La información fluye desde una capa de entrada, pasa por una o más "capas ocultas" y finalmente llega a una capa de salida.
Piensa en ello como un equipo de trabajo:
- La primera capa recibe la información inicial.
- Las capas ocultas procesan la información de manera más compleja, extrayendo características importantes.
- La última capa da la respuesta final.
Tener varias capas permite a la red resolver problemas mucho más complicados y reconocer patrones más difíciles que un solo perceptrón. La cantidad de neuronas en las capas ocultas es importante; si hay muy pocas, la red no aprenderá bien, y si hay demasiadas, puede volverse ineficiente.
Estructura de una Red Neuronal

Una red neuronal típica tiene una estructura organizada en capas:
- Capa de entrada: Aquí es donde la red recibe los datos iniciales.
- Capas ocultas: Son las capas intermedias donde se realiza la mayor parte del procesamiento y aprendizaje. Puede haber una o varias capas ocultas.
- Capa de salida: Esta capa produce la respuesta final de la red.
Cada capa puede tener un número diferente de neuronas y usar distintas formas de procesar la información. Es como tener diferentes tipos de especialistas en cada etapa del procesamiento.
Regla de Aprendizaje de la Retropropagación
La retropropagación es un tipo de aprendizaje supervisado. Esto significa que la red necesita ejemplos de entrenamiento que incluyan tanto la información de entrada como la respuesta correcta esperada.
Por ejemplo, si queremos que la red reconozca imágenes de perros, le mostraremos muchas fotos de perros (entrada) y le diremos "esto es un perro" (salida esperada).
El objetivo principal del algoritmo es ajustar las conexiones (llamadas "pesos") entre las neuronas para que el error entre la respuesta de la red y la respuesta correcta sea lo más pequeño posible. Esto se logra repitiendo el proceso de propagación hacia adelante y hacia atrás muchas veces, ajustando los pesos en cada paso.
Cuando la red comete un error, el algoritmo calcula cuánto debe cambiar cada peso para reducir ese error. Es como si la red tuviera un mapa de errores y siempre buscara el camino que la lleve a cometer menos errores.
Minimización del Error
En el aprendizaje automático, los algoritmos supervisados construyen "modelos" que predicen valores. Para ello, necesitan ejemplos donde se conozcan tanto las entradas como las salidas correctas.
Por ejemplo, si queremos predecir si un cliente comprará un producto, le damos al algoritmo datos del cliente (entrada) y si compró o no (salida esperada).
El algoritmo calcula qué tan bien se aproxima su modelo a las respuestas correctas. La "calidad" de la predicción se mide con un "error". El objetivo es que este error sea lo más bajo posible.
Para minimizar el error, el algoritmo ajusta los parámetros de la red (los "pesos") poco a poco. Es como afinar un instrumento musical: se hacen pequeños ajustes hasta que el sonido es perfecto. El proceso se detiene cuando los ajustes ya no mejoran mucho el resultado o cuando el error es muy pequeño.
Si la función que usa la red para dar sus respuestas puede ser "diferenciada" (un concepto matemático que ayuda a encontrar la dirección de mayor cambio), se puede usar un método llamado "descenso de gradiente". Este método ayuda a la red a saber en qué dirección y cuánto debe ajustar sus pesos para reducir el error de la manera más eficiente.
Red Neuronal con una Capa Oculta

Una red neuronal con una capa oculta tiene tres tipos de capas:
- Capa de entrada: Recibe la información inicial.
- Capa oculta: Procesa la información de la capa de entrada.
- Capa de salida: Produce la respuesta final de la red.
Las conexiones entre estas capas tienen "pesos" que la red ajusta durante el aprendizaje. La "función de transferencia" es una regla matemática que decide cómo se activa una neurona. Una función común es la "función sigmoidal", que ayuda a la red a aprender de manera suave y eficiente.
Descripción del Algoritmo de Retropropagación
En resumen, el algoritmo de retropropagación sigue estos pasos: 1. La red recibe una entrada y calcula su propia respuesta. 2. Compara su respuesta con la respuesta correcta y calcula el error. 3. Calcula cómo cada conexión (peso) en la última capa contribuyó al error. 4. Calcula cómo cada conexión en las capas anteriores (hacia la entrada) contribuyó al error. 5. Ajusta los pesos de todas las conexiones para reducir el error. 6. Repite todo el proceso muchas veces con diferentes ejemplos de entrenamiento hasta que la red aprenda bien.
Galería de imágenes
-
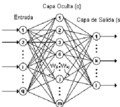
Representación de una capa oculta en una red neuronal.

Véase también
 En inglés: Backpropagation Facts for Kids
En inglés: Backpropagation Facts for Kids
