
Función hash para niños
Una función resumen, también conocida como función hash, es como una huella digital única para la información. Imagina que tienes un mensaje o un archivo muy grande. Una función hash toma esa información y la convierte en un código más corto, de tamaño fijo, que es como su "resumen" o "huella".
Este código es muy útil en las computadoras para organizar datos y, sobre todo, para la seguridad. Es una función especial que siempre da el mismo resultado para la misma entrada.

Contenido
¿De dónde viene el nombre "Hash"?
El nombre hash viene del idioma inglés y significa algo parecido a "picar y mezclar". Es una buena forma de describir lo que hace esta función: toma la información, la "pica" en pedacitos y la "mezcla" para crear un nuevo código.
Se cree que H. P. Luhn, un empleado de IBM, usó este concepto por primera vez en 1953. Sin embargo, su uso se hizo muy popular unos diez años después.
Palabras clave importantes
Cuando hablamos de funciones hash, hay algunos términos que debes conocer:
¿Qué es el Dominio y la Imagen?
- El dominio es el conjunto de todas las posibles entradas que una función hash puede recibir. Por ejemplo, si la función hash es para textos, el dominio serían todos los textos que existen.
- La imagen es el conjunto de todos los posibles códigos o "huellas" que la función hash puede producir. Estos códigos siempre tienen una longitud fija.
¿Qué es una Colisión?
Una colisión ocurre cuando dos entradas diferentes producen el mismo código hash. Piensa en ello como si dos personas tuvieran la misma huella digital, lo cual es muy raro en la vida real.
Las funciones hash están diseñadas para que las colisiones sean muy poco probables. Aunque el número de entradas posibles es enorme (incluso infinito), el número de códigos hash posibles es limitado porque tienen un tamaño fijo. Por eso, las colisiones son posibles, pero una buena función hash las minimiza al máximo.
Características de una buena Función Hash
Las funciones hash tienen varias propiedades que las hacen útiles para diferentes tareas:
Bajo costo
Calcular el código hash debe ser rápido y no requerir mucha potencia de la computadora.
Compresión
Una función hash comprime los datos. Esto significa que puede tomar una entrada muy larga y convertirla en un código hash mucho más corto.
Uniforme
Una función hash es uniforme si distribuye los códigos hash de manera equilibrada. Esto ayuda a que las colisiones sean menos frecuentes.
Determinista
Una función hash es determinista si, para la misma entrada, siempre produce exactamente el mismo código hash. Si le das el mismo mensaje hoy, mañana o dentro de un año, el código hash será idéntico. Esto es muy importante para su fiabilidad.
Resistencia a colisiones
Esta es una propiedad muy importante, especialmente en seguridad. Significa que es extremadamente difícil encontrar dos entradas diferentes que produzcan el mismo código hash. Es como si fuera casi imposible encontrar dos personas con la misma huella digital.
¿Para qué se usan las Funciones Hash?
Las funciones hash tienen muchas aplicaciones prácticas en el mundo de la informática y la seguridad:
Proteger la integridad de los datos
- Firmas digitales: Cuando firmas un documento digitalmente, en lugar de firmar todo el documento, se firma su código hash. Esto es más rápido y asegura que cualquier cambio, por pequeño que sea, en el documento original, hará que la firma no sea válida.
- Verificación de archivos: Cuando descargas un archivo de internet, a menudo se proporciona un código hash junto con él. Puedes calcular el hash del archivo que descargaste y compararlo con el que te dieron. Si coinciden, sabes que el archivo no se dañó ni fue modificado durante la descarga. Esto se usa mucho para detectar si un archivo ha sido alterado por un virus.
- Control de versiones: En el desarrollo de software, se usan hashes para saber si un archivo ha cambiado entre diferentes versiones.
Seguridad y autenticación
- Proteger contraseñas: Cuando creas una cuenta en línea, tu contraseña no se guarda directamente. En su lugar, se guarda su código hash. Cuando intentas iniciar sesión, el sistema calcula el hash de la contraseña que introduces y lo compara con el hash guardado. Si coinciden, te da acceso. De esta forma, si alguien accede a la base de datos, no verá tu contraseña real, solo su hash.
- Autenticación: Las funciones hash pueden usarse para verificar la identidad de una persona o un dispositivo sin tener que compartir información secreta directamente.
Identificación y comparación rápida de datos
- Huellas digitales de contenido: Las funciones hash pueden crear "huellas digitales" para cualquier tipo de contenido, como imágenes, videos o canciones. Esto permite identificar rápidamente si dos archivos son el mismo contenido, incluso si tienen nombres diferentes o están almacenados en lugares distintos. Por ejemplo, algunas aplicaciones de música pueden identificar una canción que está sonando comparando su huella digital de audio con una base de datos.
- Búsqueda de virus: Los programas antivirus usan hashes para identificar virus. Cada virus conocido tiene una "firma" o hash único. El antivirus escanea tus archivos, calcula sus hashes y los compara con su base de datos de firmas de virus.
- Redes de intercambio de archivos: En redes como BitTorrent, los archivos se dividen en pequeñas partes, y cada parte tiene un hash. Esto permite que el sistema verifique la integridad de cada parte y se asegure de que estás descargando el archivo correcto.
Galería de imágenes
-
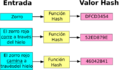
Una función de hash en funcionamiento.
Véase también
 En inglés: Hash function Facts for Kids
En inglés: Hash function Facts for Kids
