
RAID para niños
Un RAID (que viene del inglés Redundant Array of Independent Disks) es un sistema que usa varios discos duros (como los que guardan la información en tu computadora o en servidores) para trabajar juntos. En lugar de que cada disco funcione por separado, el RAID los combina para que el sistema operativo los vea como si fueran un solo disco grande.

Al usar varios discos juntos, un sistema RAID puede ofrecer varias ventajas:
- Mayor seguridad para tus datos: Si un disco falla, la información no se pierde.
- Más velocidad: Los datos se pueden leer o escribir más rápido.
- Más espacio de almacenamiento: Combina el espacio de varios discos.
Originalmente, los sistemas RAID ayudaban a usar discos más económicos para lograr una mejor capacidad, seguridad o velocidad que un solo disco más caro. Hoy en día, se usan mucho en servidores (computadoras potentes que guardan información para muchas personas) y también en algunas computadoras personales avanzadas.
Los sistemas RAID pueden ser de dos tipos principales:
- Por hardware: Usan una tarjeta especial en la computadora para gestionar los discos.
- Por software: Se gestionan mediante programas dentro del sistema operativo.
Algunos sistemas RAID pueden tener discos de repuesto (llamados hot spare). Estos discos están listos para usarse automáticamente si uno de los discos principales falla, lo que ayuda a que el sistema se recupere rápidamente.
Contenido
¿Cuáles son los tipos de RAID más comunes?
Existen diferentes formas de configurar un sistema RAID, y a cada una se le llama "nivel". Los más usados son:
- RAID 0: Para mayor velocidad.
- RAID 1: Para mayor seguridad de los datos.
- RAID 5: Un equilibrio entre velocidad y seguridad.
RAID 0: Velocidad al máximo

El RAID 0 divide los datos en partes y los guarda en dos o más discos al mismo tiempo. Imagina que tienes un libro y lo divides en dos mitades, y dos personas lo leen a la vez. Así, terminan más rápido.
- Ventaja: Es muy rápido para leer y escribir datos.
- Desventaja: No ofrece seguridad. Si uno de los discos falla, pierdes toda la información, porque ninguna parte está duplicada.
- Uso: Ideal para tareas donde la velocidad es lo más importante y no te preocupa perder los datos (por ejemplo, si son datos temporales o tienes una copia de seguridad en otro lugar).
RAID 1: Copia de seguridad instantánea

El RAID 1 crea una copia exacta de tus datos en dos o más discos. Es como tener dos espejos: todo lo que está en un disco, está también en el otro.
- Ventaja: Ofrece mucha seguridad. Si un disco falla, tienes una copia idéntica de todos tus datos en el otro disco.
- Desventaja: Solo usas la mitad del espacio total de los discos (si tienes dos discos de 1 TB, solo puedes guardar 1 TB de datos).
- Uso: Perfecto para información muy importante que no puedes permitirte perder.
RAID 5: Equilibrio entre velocidad y seguridad

El RAID 5 divide los datos entre varios discos, pero también guarda una información extra llamada "paridad" en esos mismos discos. Esta paridad es como una clave secreta que permite reconstruir los datos si uno de los discos falla.
- Ventaja: Ofrece un buen equilibrio entre velocidad y seguridad. Puedes perder un disco y tus datos seguirán a salvo.
- Desventaja: Si fallan dos discos al mismo tiempo, podrías perder la información.
- Uso: Muy popular en servidores y sistemas donde se necesita buen rendimiento y protección de datos. Necesita al menos 3 discos.
RAID 6: Doble seguridad

El RAID 6 es una versión mejorada del RAID 5. En lugar de una sola información de paridad, guarda dos. Esto significa que puede soportar el fallo de hasta dos discos al mismo tiempo sin perder datos.
- Ventaja: Mayor seguridad que RAID 5, ya que permite que fallen dos discos.
- Desventaja: Es un poco más lento para escribir datos porque tiene que calcular dos paridades.
- Uso: Para sistemas que necesitan una seguridad de datos muy alta. Necesita al menos 4 discos.
¿Qué son los niveles RAID anidados?
Algunos sistemas RAID combinan los niveles básicos para obtener más ventajas. Esto se llama "anidar" o "anidar niveles RAID". Es como construir capas: los discos físicos están abajo, y encima se construyen los niveles RAID.
- RAID 10 (o RAID 1+0): Es una combinación de RAID 1 y RAID 0. Primero, se crean grupos de discos en espejo (RAID 1) para tener seguridad. Luego, estos grupos se combinan con RAID 0 para aumentar la velocidad. Es muy rápido y seguro.

- RAID 0+1: Es lo contrario de RAID 10. Primero se agrupan discos para velocidad (RAID 0), y luego se hace una copia de seguridad de ese grupo (RAID 1). Aunque parece similar, el RAID 10 es generalmente preferido por su mejor recuperación de datos.

¿Cómo funciona la paridad?
La paridad es un método para detectar y corregir errores en los datos. En RAID, se usa para reconstruir la información cuando un disco falla. La operación principal que se usa es el "OR exclusivo" (conocido como XOR).
Imagina que tienes varios números y quieres saber si uno falta. El XOR funciona así:
- 0 XOR 0 = 0
- 0 XOR 1 = 1
- 1 XOR 0 = 1
- 1 XOR 1 = 0
Si tienes datos en varios discos y calculas el XOR de todos ellos, obtienes un valor de paridad. Si un disco falla, puedes usar los datos de los discos restantes y el valor de paridad para "deshacer" la operación XOR y encontrar los datos perdidos.
Por ejemplo, si tienes los datos A, B, C y la paridad P = A XOR B XOR C. Si pierdes B, puedes calcular B = A XOR C XOR P. ¡Es como un rompecabezas matemático que te permite recuperar la pieza que falta!
¿Qué puede y no puede hacer RAID?
Lo que RAID puede hacer
- Mejorar la disponibilidad: Si un disco falla, tus datos siguen accesibles. Esto es muy importante para empresas que no pueden permitirse que sus sistemas se detengan.
- Aumentar el rendimiento: Algunos niveles RAID (como RAID 0, 5 y 6) pueden leer y escribir datos más rápido al usar varios discos a la vez. Esto es útil para tareas que manejan archivos muy grandes, como la edición de video.
Lo que RAID no puede hacer
- Proteger contra todo tipo de pérdida de datos: RAID protege contra fallos de discos físicos, pero no contra virus, borrados accidentales, o errores de software. ¡Siempre necesitas hacer copias de seguridad de tus datos importantes!
- Simplificar la recuperación de desastres: Si todo el sistema RAID falla, recuperarlo puede ser complicado y requiere herramientas especiales.
- Mejorar el rendimiento en todas las aplicaciones: Para tareas diarias o juegos, donde se manejan muchos archivos pequeños, un RAID podría no ofrecer una mejora notable. A veces, un solo disco más rápido es mejor.
- Facilitar el traslado a un nuevo sistema: Si quieres mover tus discos RAID a una computadora diferente, la nueva computadora debe tener una controladora RAID compatible, lo cual no siempre es el caso.
Galería de imágenes
-
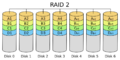
Diagrama de una configuración RAID 2.
-

Diagrama de una configuración RAID 3. Cada número representa un byte de datos; cada columna, un disco.
-

Diagrama de una configuración RAID 4. Cada número representa un bloque de datos; cada columna, un disco.
-
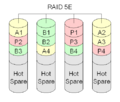
RAID 5E
-

Diagrama de una configuración RAID 0+1.
-

Diagrama de una configuración RAID 30.
-

RAID 100
-

RAID 50
-

Diagrama una configuración RAID de doble paridad.
-
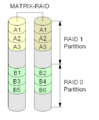
Diagrama de una configuración Matriz RAID.
-
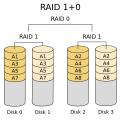
RAID 10
-
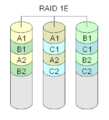
Diagrama de una configuración RAID 1E.










Véase también
 En inglés: RAID Facts for Kids
En inglés: RAID Facts for Kids
