
Normalización de bases de datos para niños
La normalización de bases de datos es un proceso muy importante cuando se diseñan bases de datos relacionales. Imagina que una base de datos es como una gran colección de archivos organizados en carpetas. La normalización es como un conjunto de reglas que aplicamos a esas carpetas y archivos para que la información esté bien organizada, sin repeticiones innecesarias y sea fácil de manejar.
El objetivo principal es evitar que la misma información se guarde varias veces en diferentes lugares, lo que podría causar errores o hacer que la base de datos sea lenta.
Contenido
- ¿Por qué es importante organizar los datos?
- Palabras clave en bases de datos
- ¿Qué son las dependencias en los datos?
- Tipos de claves en las tablas
- Formas normales: Reglas para organizar las tablas
- Las 12 reglas de Codd
- Regla 1: La regla de la información
- Regla 2: La regla del acceso garantizado
- Regla 3: Manejo de valores desconocidos
- Regla 4: La descripción de la base de datos
- Regla 5: Un lenguaje completo
- Regla 6: Actualización de vistas
- Regla 7: Operaciones en conjunto
- Regla 8: Independencia física
- Regla 9: Independencia lógica
- Regla 10: Independencia de la integridad
- Regla 11: La regla de la distribución
- Regla 12: No se puede "engañar" al sistema
- Galería de imágenes
- Véase también
¿Por qué es importante organizar los datos?
Las bases de datos relacionales se organizan, o "normalizan", para lograr varias cosas importantes:
- Evitar la repetición de datos: Imagina que tienes la dirección de un cliente guardada en diez lugares diferentes. Si el cliente se muda, tendrías que cambiar la dirección en los diez lugares. Si solo la guardas una vez, el cambio es mucho más sencillo.
- Facilitar la actualización: Al no tener datos repetidos, es más fácil y rápido cambiar la información cuando sea necesario.
- Proteger la información: Asegurarse de que los datos sean correctos y consistentes.
En una base de datos relacional, la información se guarda en "tablas", que son como hojas de cálculo. Para que una tabla funcione bien, debe cumplir algunas reglas:
- Cada tabla debe tener un nombre único.
- No puede haber dos filas (o registros) exactamente iguales.
- Todos los datos en una columna deben ser del mismo tipo (por ejemplo, solo números o solo texto).
Palabras clave en bases de datos

Para entender mejor las bases de datos, aquí tienes algunos términos importantes:
- Tabla: Es como una hoja de cálculo donde se guarda la información.
- Fila (o registro): Es una línea completa de información en una tabla, por ejemplo, todos los datos de una persona.
- Columna (o atributo): Es una categoría de información en una tabla, como "Nombre" o "Edad".
- Clave: Es un código o identificador único.
- Clave Primaria: Es una columna (o un grupo de columnas) que identifica de forma única cada fila en una tabla. Por ejemplo, el número de identificación de un estudiante.
- Clave Externa (o Foránea): Es una columna en una tabla que se conecta con la clave primaria de otra tabla. Ayuda a relacionar la información entre diferentes tablas.
- Sistema de Gestión de Bases de Datos Relacionales (SGBDR): Es el programa que usamos para crear, organizar y manejar las bases de datos.
¿Qué son las dependencias en los datos?
La normalización se basa en entender cómo se relacionan los datos entre sí. Una relación importante es la "dependencia funcional".
¿Qué es una dependencia funcional?

Una dependencia funcional significa que si conoces el valor de una columna (o un grupo de columnas), puedes saber el valor de otra columna.
Por ejemplo, si conoces el número de identificación de una persona (como el DNI en España), puedes saber su nombre y apellido. Esto se escribe así:
NúmeroDeIdentificación 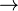 Nombre
Nombre
Esto nos ayuda a organizar las tablas de manera eficiente.
Reglas de las dependencias funcionales
Hay algunas reglas básicas que nos ayudan a entender cómo funcionan las dependencias:
Dependencia reflexiva
Si una parte de la información ya está incluida en otra, entonces la más grande puede determinar a la más pequeña. Por ejemplo, si el nombre de una persona está incluido en su número de identificación, entonces con el número de identificación podemos saber su nombre.
Dependencia aumentativa
Si una columna determina a otra, y le añades más información a la primera, seguirá determinando a la segunda (y a la información que añadiste). Ejemplo: Si NúmeroDeIdentificación Nombre, entonces NúmeroDeIdentificación, Dirección Nombre, Dirección.
Dependencia transitiva

Imagina que A determina a B, y B determina a C. Entonces, A también determina a C, aunque sea de forma indirecta. Ejemplo: FechaDeNacimiento Edad Edad PuedeConducir (porque en muchos lugares necesitas una edad mínima para conducir)
Entonces, FechaDeNacimiento PuedeConducir. Si sabes la fecha de nacimiento de alguien, puedes saber si puede conducir.
Tipos de claves en las tablas
Las claves son muy importantes para identificar y relacionar la información en las tablas.
- Clave Primaria: Es la columna o grupo de columnas que identifica de forma única cada fila en una tabla. Es como el número de carné de identidad de cada registro. Siempre debe ser única y no puede estar vacía. A menudo, es un número que aumenta automáticamente.
- Clave Candidata: A veces, una tabla puede tener varias columnas que podrían ser una clave primaria. Todas esas opciones son claves candidatas. Elegimos una de ellas para que sea la clave primaria.
- Clave Externa (o Foránea): Es una columna en una tabla que se usa para conectar esa tabla con otra. Esta columna es una clave primaria en la otra tabla. Por ejemplo, en una tabla de "Pedidos", podría haber una clave externa "ID_Cliente" que se conecta con la clave primaria "ID_Cliente" en la tabla de "Clientes".
- Clave Alternativa: Es una clave candidata que no fue elegida como clave primaria, pero que también podría identificar de forma única una fila. Por ejemplo, si el número de identificación es la clave primaria de un cliente, su número de seguridad social podría ser una clave alternativa.
- Clave Compuesta: Es una clave que está formada por más de una columna. Por ejemplo, para identificar un curso, podrías necesitar el "Código de Curso" y el "Año".
Formas normales: Reglas para organizar las tablas
Las "formas normales" son un conjunto de reglas que nos ayudan a organizar las tablas de una base de datos para que estén bien estructuradas y sin problemas. Cuantas más reglas cumpla una tabla, mejor organizada estará.
Las primeras tres formas normales son las más importantes y las que la mayoría de las bases de datos deben cumplir. Fueron creadas por un experto llamado Edgar F. Codd.
Primera Forma Normal (1FN)
Una tabla está en Primera Forma Normal si:
- Cada celda de la tabla contiene un solo valor. No hay listas de valores en una sola celda.
- Todas las filas son únicas.
- El orden de las filas y columnas no importa.
Esta forma normal ayuda a eliminar los valores repetidos dentro de una misma celda.
Segunda Forma Normal (2FN)
Una tabla está en Segunda Forma Normal si ya cumple con la Primera Forma Normal y, además, todas las columnas que no son parte de la clave primaria dependen completamente de la clave primaria. Esto significa que ninguna parte de la clave primaria puede determinar por sí sola a una columna que no es clave.
Por ejemplo, si tienes una tabla con "ID_Empleado", "ID_Proyecto" y "HorasTrabajadas", y la clave primaria es la combinación de "ID_Empleado" y "ID_Proyecto", entonces "HorasTrabajadas" debe depender de ambos. Si también tuvieras "Nombre_Empleado" en esa tabla, y "Nombre_Empleado" solo depende de "ID_Empleado" (y no de "ID_Proyecto"), entonces la tabla no estaría en 2FN. En ese caso, "Nombre_Empleado" debería ir en una tabla separada de "Empleados".
Tercera Forma Normal (3FN)
Una tabla está en Tercera Forma Normal si cumple con la Segunda Forma Normal y, además, no hay dependencias transitivas entre las columnas que no son clave. Esto significa que ninguna columna que no es clave puede depender de otra columna que tampoco es clave.
Por ejemplo, si tienes una tabla con "ID_Empleado", "Departamento" y "Jefe_Departamento", y "Jefe_Departamento" depende de "Departamento", y "Departamento" depende de "ID_Empleado", entonces "Jefe_Departamento" depende transitivamente de "ID_Empleado" a través de "Departamento". Para estar en 3FN, "Jefe_Departamento" debería estar en una tabla separada de "Departamentos".
Forma Normal de Boyce-Codd (FNBC)
Esta es una forma normal más estricta que la 3FN. Una tabla está en FNBC si cada columna que determina a otra columna es una clave candidata. Es decir, si una columna (o grupo de columnas) puede identificar de forma única a otra, entonces esa columna debe ser una clave candidata.
Cuarta Forma Normal (4FN)
Una tabla está en Cuarta Forma Normal si ya está en FNBC y no tiene "dependencias multivaluadas" que no sean funcionales. Esto es un poco más avanzado, pero básicamente evita que haya información repetida de una manera más compleja.
Quinta Forma Normal (5FN)
Una tabla está en Quinta Forma Normal si está en 4FN y no tiene ciertos tipos de dependencias que podrían causar problemas al combinar información de varias tablas.
Las 12 reglas de Codd
Edgar F. Codd, el creador del modelo de bases de datos relacionales, estableció 12 reglas para que un sistema de base de datos fuera verdaderamente "relacional". Estas reglas son como un estándar de oro para los sistemas de bases de datos. Cuantas más reglas cumpla un sistema, mejor será.
Aquí te explicamos algunas de las más importantes de forma sencilla:
Regla 1: La regla de la información
Toda la información en la base de datos debe estar guardada en tablas. Esto incluye los datos que tú guardas y también la información sobre la propia base de datos (como los nombres de las tablas y columnas).
Regla 2: La regla del acceso garantizado
Siempre debes poder encontrar cualquier dato en la base de datos usando el nombre de la tabla, la clave primaria de la fila y el nombre de la columna. Es como tener una dirección exacta para cada pieza de información.
Regla 3: Manejo de valores desconocidos
El sistema debe poder manejar la información que no se conoce o que no aplica. Para esto se usan los "valores nulos". Por ejemplo, si no sabes la dirección de correo electrónico de alguien, puedes dejar ese campo como nulo.
Regla 4: La descripción de la base de datos
La información sobre cómo está organizada la base de datos (qué tablas hay, qué columnas tienen, quién puede ver qué) también debe guardarse en tablas y ser accesible.
Regla 5: Un lenguaje completo
Debe haber al menos un lenguaje (como SQL) que permita hacer todo en la base de datos: crear tablas, añadir datos, cambiarlos, borrarlos, y controlar quién puede hacer qué.
Regla 6: Actualización de vistas
Si creas una "vista" (que es como una tabla virtual basada en otras tablas) y es posible actualizarla, el sistema debe permitirte hacerlo.
Regla 7: Operaciones en conjunto
Las operaciones para añadir, cambiar o borrar datos deben funcionar no solo para un dato a la vez, sino también para grupos de datos.
Regla 8: Independencia física
Los programas que usan la base de datos no deberían verse afectados si se cambia cómo se guardan los datos físicamente (por ejemplo, si se mueven los archivos a otro disco duro).
Regla 9: Independencia lógica
Los programas que usan la base de datos no deberían verse afectados si se hacen cambios en la estructura lógica de las tablas (por ejemplo, si se añade una nueva columna).
Regla 10: Independencia de la integridad
Las reglas que aseguran que los datos son correctos (como que la clave primaria no puede estar vacía) deben estar definidas en la base de datos misma, no en los programas que la usan.
Regla 11: La regla de la distribución
El sistema debe poder funcionar incluso si la base de datos está dividida y guardada en diferentes computadoras o lugares, sin que los programas que la usan se den cuenta de esa división.
Regla 12: No se puede "engañar" al sistema
Si el sistema tiene formas de acceder a los datos a un nivel muy bajo, estas formas no deben permitir que se rompan las reglas de integridad que se establecieron a un nivel más alto.
Galería de imágenes
-

B es funcionalmente dependiente de A.
-

Dependencia funcional transitiva.
-
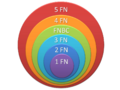
Diagrama de inclusión de todas las formas normales.

Véase también
 En inglés: Database normalisation Facts for Kids
En inglés: Database normalisation Facts for Kids
